
Zadawaj pytania swoim dokumentom
Porozmawiaj z dokumentami zamiast szukać w nich określonej treści, rozwiązanie typu open source, która umożliwia konwersację z dokumentami, jednocześnie dbając o twoją prywatność. Dzięki lokalnemu działaniu, masz pełną kontrolę nad swoimi pytaniami i danymi, bez obaw, że opuszczą one twój komputer. Zanurz się w fascynujący świat bezpiecznych i lokalnych interakcji z dokumentami, dzięki LocalGPT. Wyniki mogą cię zaskoczyć

Co to jest GPT ?
Generative Pre-trained Transformer to rodzina modeli uczenia maszynowego, która została wytrenowana na ogromnych zbiorach danych tekstowych. Te modele są wykorzystywane do wielu zastosowań, takich jak generowanie tekstu, tłumaczenie maszynowe, analiza sentymentu, odpowiedzi na pytania i wiele innych. Mogą być dostępne jako narzędzia online lub w formie oprogramowania, które można uruchomić lokalnie.
LongChain – Porozmawiaj z Dokumentami
LongChain to specyficzna technologia, która przetwarza dokumenty przed dostarczeniem ich do lokalnego modelu GPT, czyli jej konkretny przypadek użycia zależy od tego, w jaki sposób jest ona skonfigurowana i w jaki sposób przetwarza te dokumenty. Przykłady wykorzystania lokalnego GPT mogą obejmować:
- Generowanie treści: Wykorzystanie modelu GPT do generowania treści na podstawie przetworzonych dokumentów, na przykład tworzenie artykułów, raportów lub treści marketingowych.
- Tłumaczenie: Użycie modelu GPT do tłumaczenia tekstów na podstawie dostępnych dokumentów w różnych językach.
- Analiza sentymentu: Model GPT może być wykorzystany do analizy sentymentu tekstów, aby określić, czy zawartość jest pozytywna, negatywna lub neutralna.
- Kategoryzacja dokumentów: Klasyfikowanie dokumentów na podstawie ich treści w różne kategorie lub tagi.
- Odpowiadanie na pytania: Model GPT może pomóc w automatycznym odpowiadaniu na pytania na podstawie dostępnych dokumentów lub informacji.
- Rekomendacje treści: Wykorzystanie modelu do rekomendowania treści lub produktów na podstawie analizy dostępnych dokumentów i preferencji użytkownika.
- Analiza trendów: Analizowanie dokumentów w celu wykrywania trendów i informacji o rynku.
- Podsumowywanie tekstów: Tworzenie skrótów lub podsumowań długich dokumentów na podstawie ich zawartości.
W związku z tym Warto zaznaczyć, że konkretne przypadki użycia będą zależały od potrzeb i dostępnych zasobów, w tym od konkretnych możliwości narzędzia „LongChain” oraz modelu GPT.
Porozmawiaj z Dokumentami
Świat wirtualnej komunikacji staje się coraz bardziej intymny i wyrafinowany, ale równocześnie narasta obawa o naszą prywatność. Czy można zachować tajemnicę w rozmowie z maszynami? Odpowiedź brzmi: tak, dzięki LocalGPT. Ponieważ to inicjatywa typu open source, która pozwala na fascynującą konwersację z dokumentami, nie wystawiając Twojej prywatności na ryzyko. Gdzie tkwi sekret? Wszystko działa lokalnie, na Twoim własnym komputerze. Czyli oznacza to, że możesz cieszyć się pełną kontrolą nad swoimi danymi, bez obawy, że opuszczą one Twój osobisty obszar. Przekształć swoje podejście do interakcji z dokumentami i zanurz się w fascynującym świecie bezpiecznych, lokalnych rozmów dzięki LocalGPT. Teraz także masz pewność, że Twoje rozmowy są całkowicie poufne i kontrolowane wyłącznie przez Ciebie, co daje Ci pełną swobodę wyrażania swoich myśli i potrzeb wirtualnie, bez żadnych obaw o zachowanie prywatności.
Co to jest LangChain ?
LangChain to framework do tworzenia aplikacji opartych na modelach językowych. Możesz także używać LangChain do tworzenia chatbotów lub asystentów osobistych, podsumowywania, analizowania lub generowania pytań i odpowiedzi na temat dokumentów lub danych strukturalnych, pisania lub rozumienia kodu, interakcji z interfejsami API oraz tworzenia innych aplikacji korzystających z generatywnej sztucznej inteligencji .
LangChain umożliwia modelom językowym łączenie się ze źródłami danych, a także interakcję z ich środowiskami. Komponenty LangChain to modułowe abstrakcje i zbiory implementacji abstrakcji. Gotowe łańcuchy LangChain to ustrukturyzowane zespoły komponentów służące do realizacji określonych zadań wyższego poziomu. Możesz używać komponentów do dostosowywania istniejących łańcuchów i budowania nowych łańcuchów.
Funkcje 🌟 LocalGPT
- Maksymalna prywatność : Twoje dane pozostają na Twoim komputerze, zapewniając 100% bezpieczeństwa.
- Wszechstronna obsługa modeli : bezproblemowo integruj różne modele typu open source, w tym HF, GPTQ, GGML i GGUF.
- Różnorodne osadzania : wybieraj spośród szeregu osadzań typu open source.
- Wykorzystaj ponownie swój LLM : Po pobraniu możesz ponownie wykorzystać LLM bez konieczności wielokrotnego pobierania.
- Historia czatu : zapamiętuje Twoje poprzednie rozmowy (w sesji).
- API : LocalGPT posiada API, którego można używać do tworzenia aplikacji RAG.
- Interfejs graficzny : LocalGPT jest wyposażony w dwa interfejsy GUI, jeden korzysta z interfejsu API, a drugi jest samodzielny (oparty na strumieniu).
- Obsługa procesorów graficznych, procesorów i MPS : Obsługuje wiele platform od razu po wyjęciu z pudełka, rozmawiaj ze swoimi danymi za pomocą
CUDAiCPU
Szczegóły techniczne 🛠️
Jeżeli wybierasz odpowiednie modele lokalne i moc, LangChain możesz uruchomić cały potok RAG lokalnie, bez konieczności opuszczania środowiska przez jakiekolwiek dane i przy rozsądnej wydajności.
ingest.pyużywaLangChainnarzędzia do analizowania dokumentu i tworzenia osadzania lokalnie przy użyciu plikówInstructorEmbeddings. Następnie przechowuje wynik w lokalnej bazie danych wektorów, korzystając zChromamagazynu wektorów.run_localGPT.pykorzysta z lokalnego LLM, aby zrozumieć pytania i stworzyć odpowiedzi. Kontekst odpowiedzi jest pobierany z lokalnego magazynu wektorów przy użyciu wyszukiwania podobieństwa w celu zlokalizowania odpowiedniego fragmentu kontekstu z dokumentów.- Możesz zastąpić ten lokalny LLM dowolnym innym LLM z HuggingFace. Upewnij się, że wybrany LLM jest w formacie HF.
Zbudowany przy użyciu 🧩
Porozmawiaj z Dokumentami
Konfiguracja środowiska 🌍
- 📥 Sklonuj repozytorium za pomocą git:
git clone https://github.com/PromtEngineer/localGPT.gitOtwórz Terminal w twoim systemie linux i wklej adres, zauważ ze ja jestem katalogu Downloads

cd localGPT

- 🐍 Zainstaluj Condę do zarządzania środowiskiem wirtualnym. Utwórz i aktywuj nowe środowisko wirtualne.
Instalacja minicondy w 3 krokach:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shchmod +x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
Stwórz środowisko wirtualne conda o nazwie localGPT
conda create -n localGPT python=3.10.0 conda activate localGPT
- 🛠️ Zainstaluj zależności za pomocą pip
Aby skonfigurować środowisko do uruchomienia kodu, najpierw zainstaluj wszystkie wymagania:
pip install -r requirements.txt
Pozyskiwanie własnych danych.
Umieść pliki w folderze SOURCE_DOCUMENTS. Możesz umieścić wiele folderów w SOURCE_DOCUMENTS, a kod będzie rekursywnie czytać Twoje pliki.
Przykładowy plik : Wpływ-Internetu-na-rozwoj-nowych-wiezi-spolecznych.pdf
Porozmawiaj z Dokumentami – Analizuj dane
Uruchom następujące polecenie, aby pozyskać wszystkie dane. Jeśli masz kartę graficzną Nvidia konfigurację w swoim systemie jest domyślna:
python ingest.pyZobaczysz następujące dane wyjściowe:
Użyj argumentu typu urządzenia, aby określić dane urządzenie CPU=Procesor
python ingest.py --device_type cpupython ingest.py --device_type mpsSkorzystaj z pomocy, aby uzyskać pełną listę obsługiwanych urządzeń.
python ingest.py --helpPrzykład 1 – Dokument – wpływ Internetu na rozwój więzi społecznych.pdf
python ingest.pySpowoduje to utworzenie nowego folderu o nazwie DB i użycie go w nowo utworzonym magazynie wektorowym. Czyli Możesz przyjąć dowolną liczbę dokumentów, a wszystkie zostaną zgromadzone w lokalnej bazie danych osadzania. Jeśli chcesz zacząć od pustej bazy danych, usuń DB i ponownie zarejestruj swoje dokumenty.
Uwaga: Ponieważ przy pierwszym uruchomieniu będzie potrzebny dostęp do Internetu, aby pobrać model osadzania (domyślnie: Instructor Embedding). W kolejnych uruchomieniach żadne dane nie opuszczą Twojego środowiska lokalnego i możesz je przyjmować bez połączenia z Internetem.

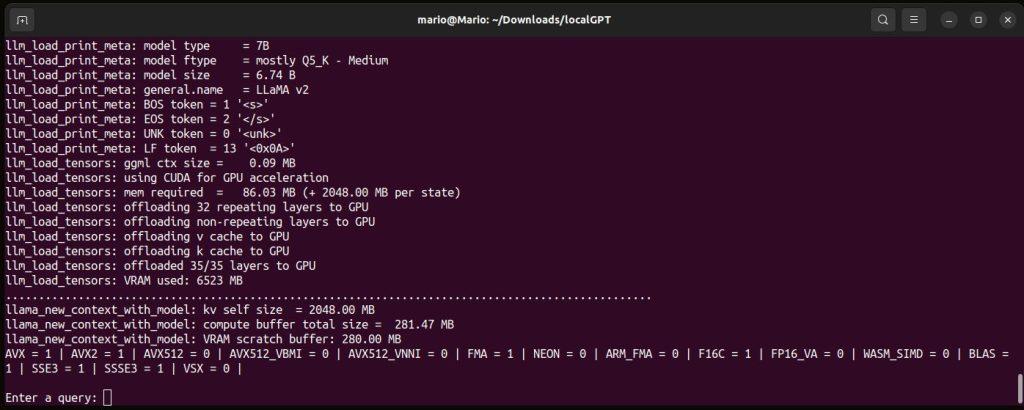
Foto nad nami pokazuje 2 terminale , górny to menadżer plików MC a dolny to środowisko condy „localGPT”
python ingest.py Komenda powyżej spowoduje że LangChain, przeanalizuje dokument i zamieni go w bazę gotową do odpytywania


Porozmawiaj z Dokumentami – Obsługiwane formaty plików:
LocalGPT używa LangChain do ładowania plików. Kod w constants.py używa DOCUMENT_MAP słownika do mapowania formatu pliku na odpowiedni moduł ładujący. Aby dodać obsługę innego formatu pliku, po prostu dodaj ten słownik z formatem pliku i odpowiednim modułem ładującym z LangChain
DOCUMENT_MAP = {
".txt": TextLoader,
".md": TextLoader,
".py": TextLoader,
".pdf": PDFMinerLoader,
".csv": CSVLoader,
".xls": UnstructuredExcelLoader,
".xlsx": UnstructuredExcelLoader,
".docx": Docx2txtLoader,
".doc": Docx2txtLoader,
}Zadawaj pytania do swoich dokumentów lokalnie
Aby porozmawiać z dokumentami, uruchom następujące polecenie
(domyślnie będzie działać na cuda – nvidia)
Porozmawiaj z Dokumentami
python run_localGPT.py
Spowoduje to załadowanie pozyskanego magazynu wektorów i modelu osadzania. Zostanie wyświetlony monit:> Enter a query: ( Zadaj pytanie: )
Przykład: Pytanie co to jest anime ? ( wpływ Internetu na rozwój więzi społecznych.pdf )

Po wygenerowaniu odpowiedzi możesz zadać kolejne pytanie ale bez ponownego uruchamiania skryptu, wystarczy ponownie poczekać na monit.
Przykład : Pytanie co to jest Manga ? ( wpływ Internetu na rozwój więzi społecznych.pdf )

Uwaga: gdy uruchomisz tę opcję po raz pierwszy, do pobrania LLM będzie potrzebne połączenie internetowe (domyślnie:TheBloke/Llama-2-7b-Chat-GGUF). Następnie możesz wyłączyć połączenie internetowe, a wnioskowanie skryptu będzie nadal działać , żadne dane nie wydostają się z Twojego środowiska lokalnego.
Wpisz, exit aby zakończyć skrypt.
Dodatkowe opcje w run_localGPT.py
Możesz użyć --show_sourcesflagi with, run_localGPT.py aby pokazać, które fragmenty zostały pobrane przez model osadzający. Domyślnie pokaże 4 różne źródła/fragmenty. Możesz zmienić liczbę źródeł/porcji
python run_localGPT.py --show_sourcesInną opcją jest włączenie historii czatów. Uwaga : ta opcja jest domyślnie wyłączona i można ją włączyć za pomocą --use_history flagi. Okno kontekstowe jest ograniczone, więc pamiętaj, że włączenie historii z niego skorzysta i może się przepełnić
python run_localGPT.py --use_historyUruchom graficzny interfejs użytkownika
- Otwórz
constants.pyw wybranym przez siebie edytorze i w zależności od wyboru dodaj LLM, którego chcesz użyć. Domyślnie zastosowany zostanie następujący model:MODEL_ID = „TheBloke/Llama-2-7b-Chat-GGUF” MODEL_BASENAME = „llama-2-7b-chat.Q4_K_M.gguf” - Otwórz terminal i aktywuj środowisko Pythona zawierające zależności zainstalowane z pliku require.txt.
- Przejdź do katalogu
/LOCALGPT. - Uruchom następujące polecenie
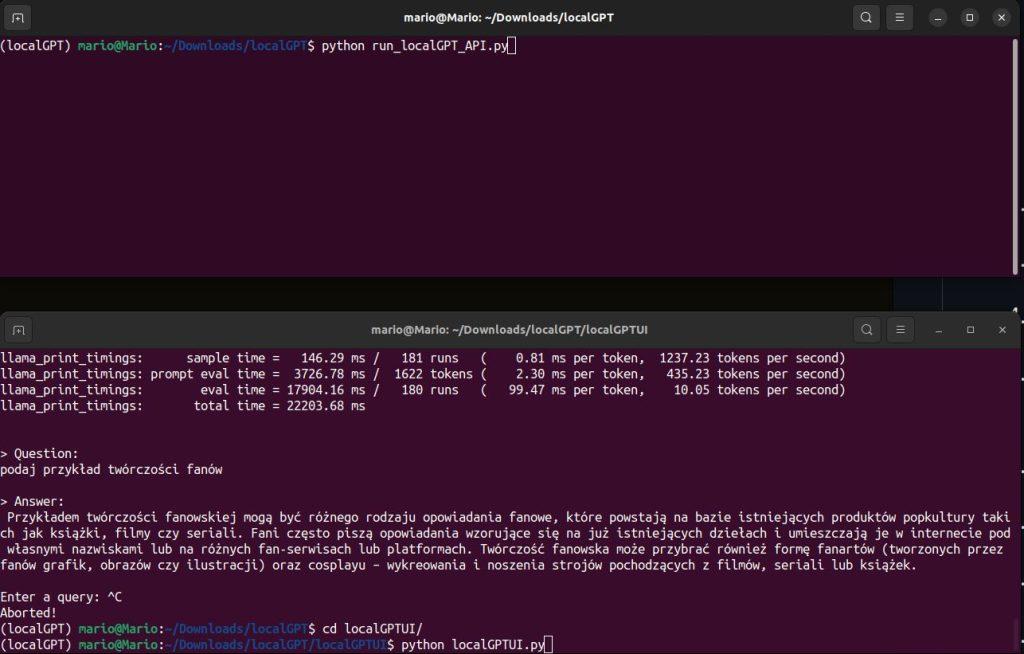
python run_localGPT_API.py. Interfejs API powinien działać. - Poczekaj, aż wszystko się załaduje. Powinieneś zobaczyć coś takiego
INFO:werkzeug:Press CTRL+C to quit. - Otwórz drugi terminal i aktywuj to samo środowisko Pythona.
- Przejdź do katalogu
/LOCALGPT/localGPTUI. - Uruchom polecenie
python localGPTUI.py. - Otwórz przeglądarkę internetową i przejdź do adresu
http://localhost:5111/
Graficzny interfejs użytkownika
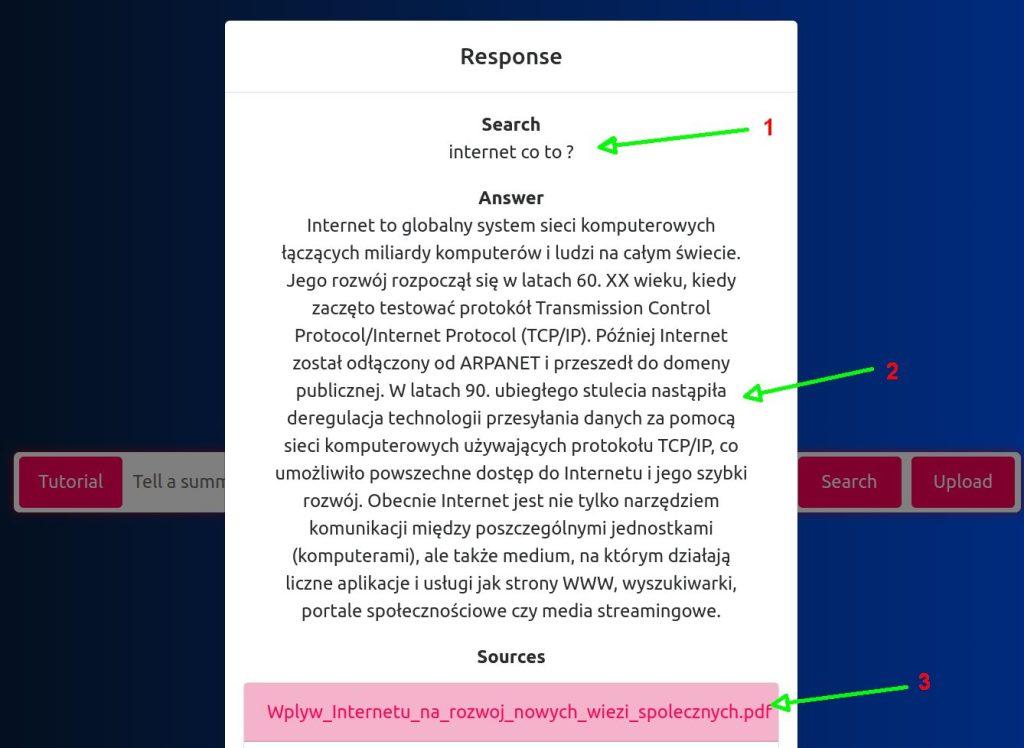
- Pytanie
- Odpowiedź
- Dokument
Porozmawiaj z Dokumentami
Przykład : Charakterystyka Geralta z Rivi
w związku z tym wszedłem na 3 strony o tematyce wiedźmińskiej , skopiowałem z forum kilka opisów Geralta, wszystkie opisy umieściłem w jednym pliku tekstowym ( Charakterystyka-Geralta.txt )
wygenerowałem bazę -> python ingest.py
Porozmawiaj z Dokumentami -> python run_localGPT.py

Jak wybrać różne modele LLM?
Aby zmienić modele, musisz ustawić oba MODEL_ID MODEL_BASENAME.
- Otwórz
constants.pyw wybranym przez siebie edytorze. - Zmień
MODEL_IDMODEL_BASENAME. Jeśli używasz modelu skwantowanego (GGML,GPTQ,GGUF), musisz podaćMODEL_BASENAME. W przypadku modeli niekwantyzowanych ustawMODEL_BASENAMEnaNONE - Istnieje wiele przykładowych modeli z HuggingFace, które zostały już przetestowane pod kątem działania z oryginalnie wyszkolonym modelem (kończącym się na HF lub posiadającym rozszerzenie .bin w swoich „Plikach i wersjach”) oraz modele skwantowane (kończące się na GPTQ lub mające .no-act-order lub .safetensors w swoich „Plikach i wersjach”).
- Dla modeli, które kończą się na HF lub mają rozszerzenie .bin w „Plikach i wersjach” na stronie HuggingFace.
- Upewnij się, że masz
MODEL_IDwybrane. Na przykład ->MODEL_ID = "TheBloke/guanaco-7B-HF" - Przejdź do repozytorium HuggingFace
- Upewnij się, że masz
- Dla modeli, które zawierają GPTQ w nazwie i/lub mają rozszerzenie .no-act-order lub .safetensors w sekcji „Pliki i wersje na stronie HuggingFace”.
- Upewnij się, że masz
MODEL_IDwybrane. Na przykład -> model_id ="TheBloke/wizardLM-7B-GPTQ" - Przejdź do odpowiedniego repozytorium HuggingFace i wybierz „Pliki i wersje”.
- Wybierz jedną z nazw modeli i ustaw ją jako
MODEL_BASENAME. Na przykład ->MODEL_BASENAME = "wizardLM-7B-GPTQ-4bit.compat.no-act-order.safetensors"
- Upewnij się, że masz
- Wykonaj te same kroki dla modeli
GGUFiGGML.
Wymagania dotyczące karty graficznej i pamięci VRAM
Poniżej przedstawiono wymagania dotyczące pamięci VRAM dla różnych modeli w zależności od ich rozmiaru (miliardy parametrów).Także szacunki w tabeli nie uwzględniają pamięci VRAM wykorzystywanej przez modele Embedding, które w zależności od modelu wykorzystują dodatkowe 2 GB–7 GB pamięci VRAM.
| Rozmiar trybu (B) | 32 | 16 | GPTQ 8bit | GPTQ 4-bitowe |
|---|---|---|---|---|
| 7B | 28 GB | 14 GB | 7 GB – 9 GB | 3,5 GB – 5 GB |
| 13B | 52 GB | 26 GB | 13 GB – 15 GB | 6,5 GB – 8 GB |
| 32B | 130 GB | 65 GB | 32,5 GB – 35 GB | 16,25 GB – 19 GB |
| 65B | 260,8 GB | 130,4 GB | 65,2 GB – 67 GB | 32,6 GB – 35 GB |
Porozmawiaj z Dokumentami – Podsumowanie
Jeśli potrzebujesz wykorzystać lokalny model GPT, będziesz musiał dostosować go do swoich konkretnych potrzeb i trenować go na odpowiednich danych, To wymaga pewnej wiedzy na temat uczenia maszynowego i przetwarzania języka naturalnego. Istnieje wiele dostępnych narzędzi i bibliotek, takich jak Hugging Face Transformers, które umożliwiają pracę z lokalnymi modelami GPT.
Porozmawiaj z Dokumentami Extra
Jeśli bardziej przyjrzałeś się moim zrzutom ekranu to zauważyłeś na pewno że moje metody uczenia opierały się na różnych dokumentach, lecz nic nie stoi na przeszkodzie aby stworzyć różne bazy dla różnych środowisk i instytucji.

Porozmawiaj z Dokumentami
Środowisko: Kancelaria adwokacka
Kancelaria adwokacka dokumenty: KodeksKarny.pdf , KodeksCywilny.pdf , KodeksPracy.pdf , KodeksRodzinny.pdf , Konstytucja.pdf , PrawoBudowlane.pdf , KodekWykroczeń.pdf
Także oto prostym sposobem możemy zadawać pytania z zakresu wiedzy zawartego w powyższych dokumentach, niewątpliwie jest to duża oszczędność czasu i pieniędzy, a wyniki mogą zaskoczyć .
Poradnik instalacji i konfiguracji LocalGPT
Zachęcam do innych poradników:
Whisper system automatycznego rozpoznawania mowy
Przekierowywanie Portów na Routerze
Popraw bezpieczeństwo komputera
Sztuczna inteligencja – ChaptGPT
Sztuczna inteligencja zamiana twarzy DeepFake