
Jak uwaga zastąpiła powtarzalność i zmieniła zasady sztucznej inteligencji
Transformers = sztuczna inteligencja. Są momenty w historii technologii, które definiują jej przyszłość. Lato 2017 roku było jednym z takich punktów zwrotnych. Wtedy właśnie świat badawczy sztucznej inteligencji, niemal niezauważenie, stanął na progu rewolucji. Publikacja „Attention Is All You Need” nie trafiła na pierwsze strony gazet ani do masowych mediów. Zamiast tego, w cichych kuluarach konferencji NeurIPS, grupa badaczy Google Brain zaprezentowała pracę, która zapoczątkowała nową erę w rozwoju AI. 24 Grudnia Julio Franco napisał ciekawy artykuł na temat rozwoju sztucznej inteligencji, oto część dla zainteresowanych Ai

Latem 2017 roku grupa badaczy Google Brain po cichu opublikowała artykuł, który na zawsze zmienił trajektorię sztucznej inteligencji. Publikacja naukowa zatytułowana „Attention Is All You Need” (Uwaga to wszystko, czego potrzebujesz) nie pojawiła się z efektownymi przemówieniami ani wiadomościami na pierwszej stronie. Zamiast tego zadebiutowała na konferencji Neural Information Processing Systems ( NeurIPS ), technicznym spotkaniu, na którym nowatorskie pomysły często gotują się przez lata, zanim dotrą do głównego nurtu.
Transformers = sztuczna inteligencja
Mało kto spoza środowiska badawczego zajmującego się sztuczną inteligencją wiedział wówczas, że niniejszy artykuł miał położyć podwaliny pod niemal każdy ważniejszy generatywny model sztucznej inteligencji. Dzisiaj słyszymy o GPT OpenAI do wariantów LLaMA Meta, BERT, Claude, Bard i tak dalej.
Transformer to innowacyjna architektura sieci neuronowej, która zmiata stare założenia przetwarzania sekwencyjnego. Zamiast liniowego, krok po kroku przetwarzania, Transformer obejmuje mechanizm paralelizowalny, zakotwiczony w technice znanej jako samo uwaga. W ciągu kilku miesięcy Transformer zrewolucjonizował sposób, w jaki maszyny rozumieją język.
Niektóre ilustracje w tym artykule zostały wygenerowane przez AI. Podpowiedź w nagłówku : gigantyczny robot górujący nad krajobrazem miasta w stylu Eva-01 z Neon Genesis Evangelion autorstwa Gainax, 4k. Obraz powyżej, render 3D autorstwa BoliviaInteligente .
Transformers = sztuczna inteligencja – nowy model
Przed Transformerem najnowocześniejsze przetwarzanie języka naturalnego (NLP) opierało się w dużej mierze na rekurencyjnych sieciach neuronowych (RNN) i ich udoskonaleniach – LSTM (Long Short-Term Memory networks) i GRU (Gated Recurrent Units). Te rekurencyjne sieci neuronowe przetwarzały tekst słowo po słowie (lub token po tokenie), przekazując ukryty stan, który miał kodować wszystko, co do tej pory przeczytano.
Ten proces wydawał się intuicyjny… w końcu czytamy tekst od lewej do prawej, więc dlaczego model miałby nie być taki sam?
Paralelizacja = Transformers = sztuczna inteligencja
Ale te starsze architektury miały krytyczne niedociągnięcia. Po pierwsze, miały problemy z bardzo długimi zdaniami. Kiedy LSTM docierał do końca akapitu, kontekst z początku często wydawał się wyblakłym wspomnieniem. Paralelizacja była również trudna, ponieważ każdy krok zależał od poprzedniego. Ta dziedzina rozpaczliwie potrzebowała sposobu na przetwarzanie sekwencji bez tkwienia w liniowej rutynie.

Porównanie architektur RNN, LSTM, GRU i Transformer, podkreślające ich kluczowe komponenty i mechanizmy przetwarzania danych sekwencyjnych. Źródło: aiml.com
Mechanizm uwagi
Badacze Google Brain postanowili zmienić tę dynamikę. Ich rozwiązanie było myląco proste: całkowicie pozbyć się rekurencji. Zamiast tego zaprojektowali model, który mógł jednocześnie analizować każde słowo w zdaniu i ustalać, jak każde słowo jest powiązane z każdym innym słowem.
Ta sprytna sztuczka – zwana „mechanizmem uwagi” – pozwoliła modelowi skupić się na najbardziej istotnych częściach zdania bez obliczeniowego bagażu rekurencji. Rezultatem był Transformer : szybki, paralelizowalny i dziwnie dobry w obsłudze kontekstu w długich fragmentach tekstu.
Transformers = sztuczna inteligencja – przełom
Przełomowym pomysłem było to, że „uwaga”, a nie pamięć sekwencyjna, może być prawdziwym silnikiem rozumienia języka. Mechanizmy uwagi istniały już we wcześniejszych modelach, ale Transformer podniósł uwagę z roli drugoplanowej do gwiazdy przedstawienia. Bez pełnej struktury uwagi Transformera generatywna sztuczna inteligencja, jaką znamy, prawdopodobnie nadal tkwiłaby w wolniejszych, bardziej ograniczonych paradygmatach.

Serendipity i AI. Podpowiedź
obrazkowa : sens życia
Ale skąd wziął się ten pomysł w Google Brain? Historia jest przesiąknięta rodzajem serendipity i intelektualnego krzyżowego zapylania, które definiują badania nad sztuczną inteligencją. Insiderzy opowiadają o nieformalnych sesjach burzy mózgów, podczas których badacze z różnych zespołów porównywali notatki na temat tego, w jaki sposób mechanizmy uwagi pomagały rozwiązywać zadania tłumaczeniowe lub poprawiały dopasowanie zdań źródłowych do docelowych.
Odbywały się debaty w kawiarniach nad tym, czy konieczność powtarzania była tylko reliktem starego myślenia. Niektórzy badacze wspominają „korytarzowe sesje coachingowe”, podczas których radykalny wówczas pomysł – całkowite usunięcie RNN – był poddawany dyskusji, kwestionowany i dopracowywany, zanim zespół ostatecznie zdecydował się na zakodowanie go.
Część genialności tego transformatora polega na tym, że umożliwia on bardzo szybkie i wydajne trenowanie na ogromnych zbiorach danych.
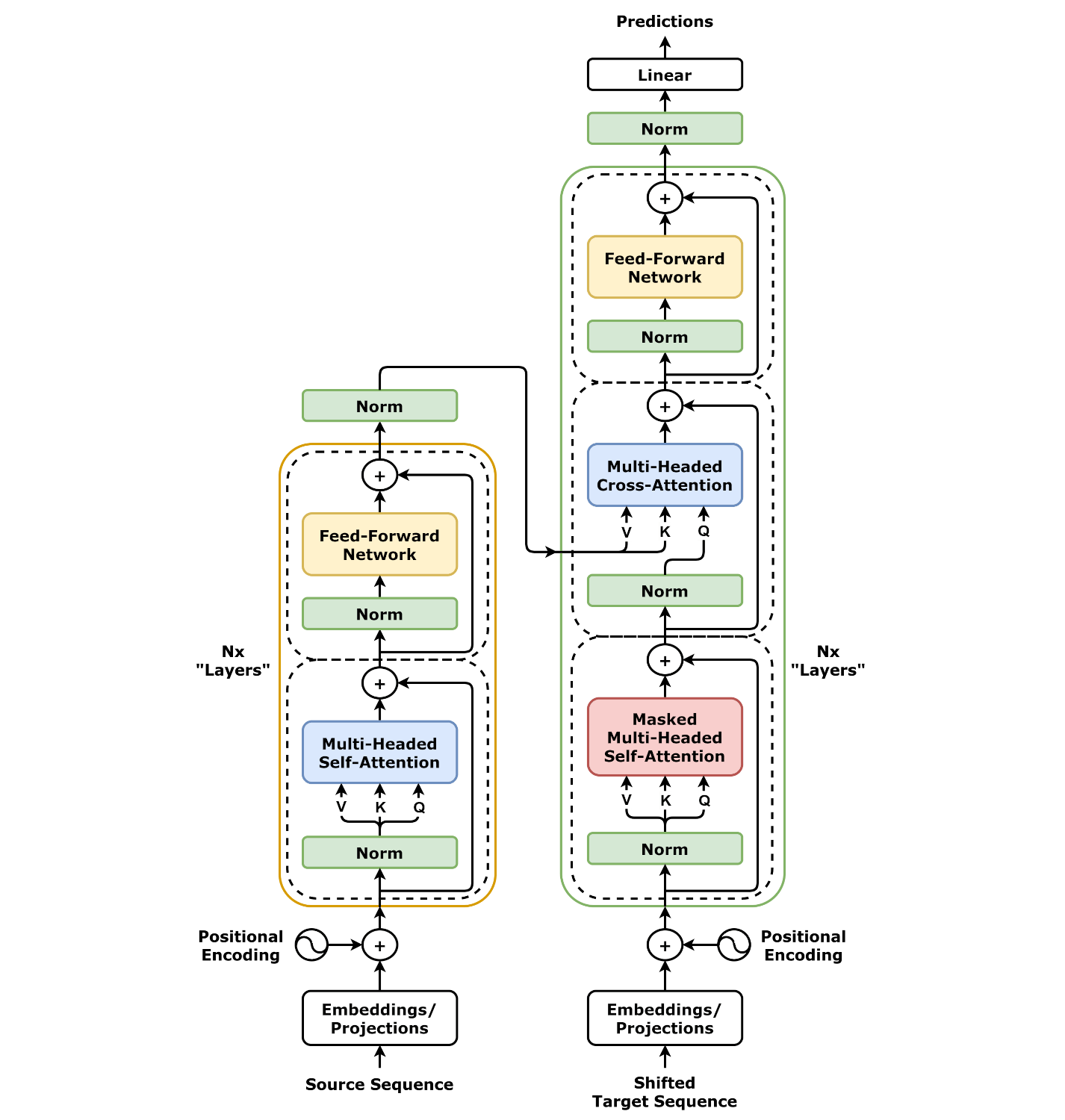
Architektura Transformera wykorzystuje dwie główne części: koder i dekoder . Koder przetwarza dane wejściowe i tworzy szczegółową, znaczącą reprezentację tych danych, używając warstw samo uwagi i prostych sieci neuronowych. Dekoder działa podobnie, ale koncentruje się na wcześniej wygenerowanym wyjściu (jak w generowaniu tekstu), a także wykorzystuje informacje z kodera.
{kind=link}
Częścią genialności tego projektu jest to, że umożliwiał on bardzo szybkie i wydajne trenowanie na ogromnych zestawach danych. Często powtarzaną anegdotą z wczesnych dni rozwoju Transformera jest to, że niektórzy inżynierowie Google początkowo nie zdawali sobie sprawy z zakresu potencjału tego modelu.
Narodziny Ai Transformers = sztuczna inteligencja
Wiedzieli, że jest dobry – znacznie lepszy niż poprzednie modele oparte na RNN w przypadku niektórych zadań językowych – ale pomysł, że może zrewolucjonizować całą dziedzinę AI, wciąż się rozwijał. Dopiero gdy architektura została publicznie wydana, a entuzjaści na całym świecie zaczęli eksperymentować, prawdziwa moc Transformera stała się niezaprzeczalna.
Renesans w modelach językowych – Google Transformers
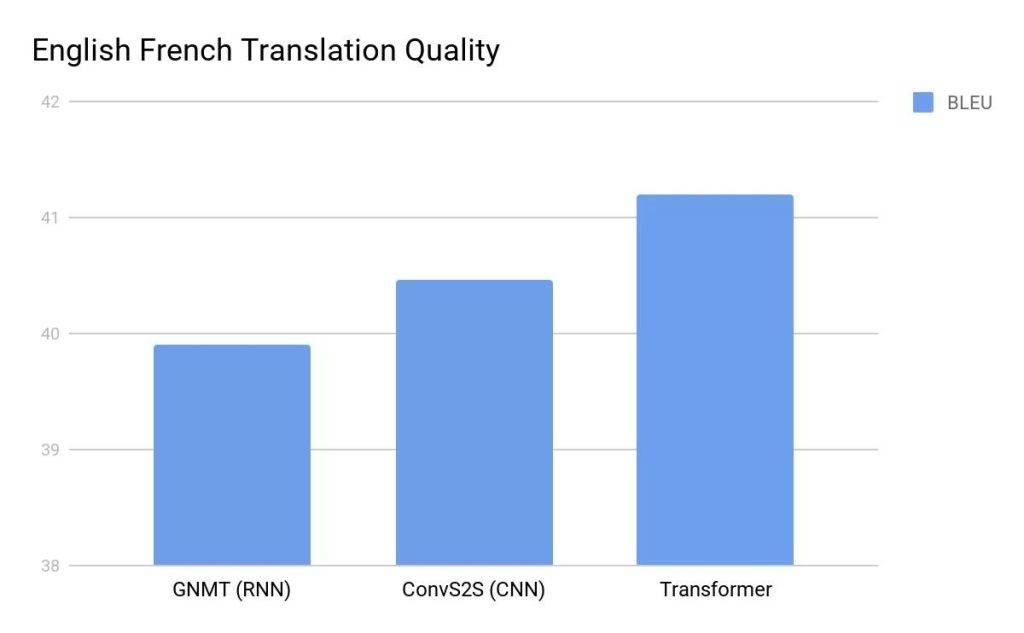
Kiedy Google Brain opublikował artykuł z 2017 r., społeczność NLP zareagowała najpierw z ciekawością, a potem ze zdziwieniem. Architektura Transformer okazała się lepsza od najlepszych modeli tłumaczenia maszynowego w takich zadaniach, jak testy porównawcze WMT z języka angielskiego na niemiecki i z języka angielskiego na francuski. Ale nie chodziło tylko o wydajność – badacze szybko zdali sobie sprawę, że Transformer jest o rzędy wielkości bardziej paralelizowalny. Czasy szkolenia gwałtownie się skróciły. Nagle zadania, które kiedyś zajmowały dni lub tygodnie, można było wykonać w ułamku czasu na tym samym sprzęcie.
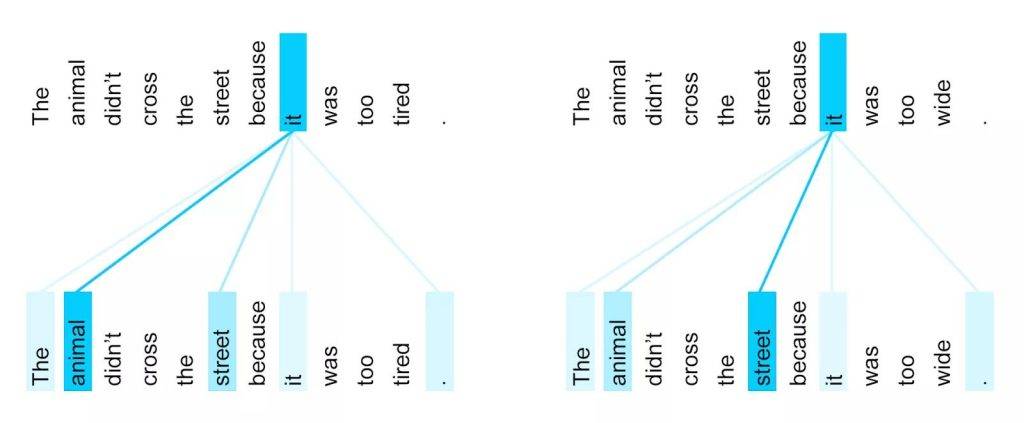
Wzór samouwagi enkodera dla słowa „it”, zaobserwowany między 5. i 6. warstwą modelu Transformer wytrenowanego pod kątem tłumaczenia z języka angielskiego na francuski
W ciągu roku od wprowadzenia model Transformer zainspirował falę innowacji. Sam Google wykorzystał architekturę Transformer do stworzenia BERT (Bidirectional Encoder Representations from Transformers). BERT radykalnie poprawił sposób, w jaki maszyny rozumiały język, zajmując pierwsze miejsce w wielu testach porównawczych NLP. Wkrótce znalazł zastosowanie w codziennych produktach, takich jak Google Search, dyskretnie ulepszając sposób interpretacji zapytań.
Media odkryły kunszt GPT i pokazały niezliczone przykłady – czasami oszałamiające, czasami śmiesznie nietrafione.
Prawie jednocześnie OpenAI przejął projekt Transformera i poszedł w innym kierunku, tworząc GPT (Generative Pre-trained Transformers).
GPT-1 i GPT-2 zasugerowały moc skalowania. W przypadku GPT-3 nie można było już ignorować, jak dobre te systemy były w tworzeniu tekstu podobnego do ludzkiego i rozumowaniu za pomocą złożonych podpowiedzi.
Pierwsza wersja ChatGPT (koniec 2022 r.) wykorzystywała udoskonalony model GPT-3.5, był to przełomowy moment. ChatGPT mógł generować niepokojąco spójny tekst, tłumaczyć języki, pisać fragmenty kodu, a nawet tworzyć poezję. Nagle zdolność maszyny do produkowania tekstu podobnego do ludzkiego przestała być mrzonką, a stała się namacalną rzeczywistością .

Media odkryły kunszt GPT i pokazały niezliczone przykłady – czasami oszałamiające, czasami zabawnie nietrafione. Publiczność była zarówno zachwycona, jak i zdenerwowana. Pomysł kreatywności wspomaganej przez AI przeniósł się z science fiction do codziennej rozmowy. Ta fala postępu – napędzana przez Transformera – przekształciła AI ze specjalistycznego narzędzia w uniwersalny silnik rozumowania.
Ale Transformer nie jest dobry tylko w tekście. Naukowcy odkryli, że mechanizmy uwagi mogą działać w różnych typach danych – obrazach, muzyce, kodzie.
Dalsza część artykułu pod adresem : https://www.techspot.com/article/2933-meet-transformers-ai/
Zachęcam do innych poradników:
Whisper system automatycznego rozpoznawania mowy
Przekierowywanie Portów na Routerze
Popraw bezpieczeństwo komputera
Sztuczna inteligencja – ChaptGPT
Serwis komputerowy Katowice
Anonimowość w sieci – Topowe programy
Przyspiesz działanie komputera
Awaria Windows update – crowdstrike BSOD naprawa