
Sztuczna inteligencja zamiana twarzy na video
Witaj w tym artykule poświęconym programowi DeepFaceLab! Jeśli marzyłeś o możliwości zmiany twarzy na wideo, skorzystaj z aplikacji DeepFaceLab. Bez wątpienia jest to Zaawansowane narzędzie do głębokiej analizy obrazów, które pozwala na manipulację twarzy w czasie rzeczywistym. W tym wpisie przyjrzymy się, jak wprowadzać te fascynujące technologie, jak korzystać z programu i jakie zastosowanie może mieć w świecie wideo.
DeepFaceLab to jeden z najpotężniejszych i najlepszych narzędzi do manipulacji twarzy, oczywiście darmowy, co czyni go jeszcze bardziej dostępnym dla każdego. Dzięki specjalnej technologii opartej na sztuczną inteligencję program potrafi rozpoznawać i analizować elementy twarzy na wideo, w rezultacie to otwiera całkiem nowe możliwości w edycji wideo. Od zmiany wyrazu twarzy postaci w filmach, po kreatywnych eksperymentach z efektami specjalnymi – DeepFaceLab pozwala na zachowanie efektów, które jeszcze były domeną wyłącznie uczęszczających na studia filmowe.
Opis – Sztuczna inteligencja Zamiana twarzy AI
Pamiętaj !
Nagłówki CZERWONE to ważne komendy, polecenia, skrypty
ZIELONE to OPCJONALNE komendy, polecenia
Nagłówki FIOLETOWE to INFORMACJE
NIEBIESKIE to narzędzia
W częściach tego artykułu omówimy, jakie są główne funkcje i cechy programu DeepFaceLab, jak schemat go do operacji na wideo oraz jakie są potencjalne zastosowania tego narzędzia w różnych działaniach. Jeśli jesteś ciekawy, jak wygląda proces zmiany twarzy na wideo w praktyce i jakie efekty możesz wykorzystać dzięki DeepFaceLab, do wykorzystania do analizy dołączonych fragmentów tego artykułu.
Zauważ, że fascynująca podróż w światową edycja wideo wspomaga sztuczną inteligencję i odkryj, jak DeepFaceLab może odmienić sposób, w jaki myślimy o manipulacji twarzy na wideo!
Co to jest DeepFaceLab?
DeepFaceLab (DFL) to wiodące oprogramowanie do tworzenia deepfake. Dlatego Większość wysokiej jakości deepfake’ów jest tworzonych przy użyciu DeepFaceLab. DFL zapewnia kompleksowe rozwiązanie do tworzenia głębokich podróbek, od zbierania i sprawdzania danych po szkolenie modeli i końcowe wyjście wideo.
DeepFaceLab, dominująca obecnie platforma deepfake do zamiany twarzy
Przeczytaj więcej w dokumencie DeepFaceLab: DeepFaceLab: Zintegrowana, elastyczna i rozszerzalna platforma wymiany twarzy.
Omówienie procesu Deepfake
Sztuczna inteligencja zamiana twarzy
Typowy deepfake zaczyna się od 2 filmów: źródłowego i docelowego. Źródłowy film zawiera twarz do deepfake; fałszywą osobę do umieszczenia w filmie. Miejscem docelowym jest film, w którym chcesz umieścić fałszywą twarz; twarz, którą chcesz zastąpić deepfake. Najpierw poszczególne klatki każdego filmu są konwertowane na sekwencję obrazów. Następnie DeepFaceLab może wykryć twarze na każdym obrazie i utworzyć osobny plik dla każdej twarzy z osadzonymi ważnymi metadanymi. Te kolekcje obrazów (zestawy twarzy) są następnie czyszczone przez usuwanie fałszywych wykrytych twarzy i innych niechcianych twarzy. Następnie DeepFaceLab wytrenuje sieć neuronową, aby nauczyła się nowej twarzy deepfake na podstawie dostarczonych obrazów. Następnie twarz deepfake jest nakładana na oryginalne obrazy docelowe i ostatecznie konwertowana z powrotem na wideo.
Czym charakteryzuje się dobry deepfake?
Charakterystyka Sztucznej inteligencji do zamiany twarzy
Technicznie rzecz biorąc, DeepFaceLab może stworzyć deepfake z zaledwie kilku obrazów. Jednak najlepsze rezultaty można uzyskać, korzystając z różnorodnych obrazów źródłowych o wysokiej jakości z różnymi wyrazami twarzy i różnymi warunkami oświetleniowymi. Dodatkowo twarze źródłowa i docelowa powinny mieć podobnie ukształtowane głowy i szczęki, aby ostateczna kompozycja była bardziej przekonująca. Ponadto obrazy źródłowe powinny mieć spójne cechy (takie jak zarost i makijaż), powinny pochodzić z krótkiego przedziału wiekowego (w ciągu kilku lat) i powinny mieć pewne podobieństwa z twarzą docelową. Im bardziej twarz źródłowa przypomina twarz docelową, tym lepszy będzie deepfake. Poświęcenie większej ilości czasu na przygotowanie danych na początku bardzo się opłaci w dłuższej perspektywie.

Schemat: Kąty ludzkiej głowy
Sztuczna inteligencja zamiana twarzy
Istnieje szereg kroków, które należy wykonać, aby stworzyć deepfake, w tym kilka faz szkoleniowych i dziesiątki opcji wprowadzania danych. Chociaż w tym przewodniku można zalecić proces, którego należy przestrzegać, każdy projekt jest inny iz biegiem czasu pogłębisz zrozumienie oprogramowania i sformułujesz własne procesy. Podobnie jak w przypadku każdego innego narzędzia kreatywnego, dzięki ćwiczeniom staniesz się lepszy w korzystaniu z DeepFaceLab. Możesz przetestować opcje, aby zobaczyć, co robią dla siebie, i poświęcić trochę czasu na przeprowadzenie eksperymentów i poznanie nowych funkcji.
DeepFaceLab może być również używany w tandemie z innym oprogramowaniem do przetwarzania obrazu i wideo. Narzędzia do ulepszania obrazu, edycja i przetwarzanie efektów oraz manipulacja dźwiękiem mogą przyczynić się do uzyskania bardziej realistycznego rezultatu, dlatego warto sprubować.
Sztuczna inteligencja zamiana twarzy na video
Pobierz i zainstaluj DeepFaceLab
| Kompilacje Windowsa | Link do pobrania |
|---|---|
| Mega.nz (najnowsze kompilacje) | Pobierz DeepFaceLab 2.0 z Mega.nz |
| Torrent (najnowsze i poprzednie kompilacje) | Pobierz DeepFaceLab z Torrent Magnet Link |
| Inny system operacyjny | Link do pobrania |
|---|---|
| Sprawdź repozytorium GitHub DeepFaceLab | Pobierz DeepFaceLab z GitHub |
Odwiedź GitHub.com/iperov/DeepFaceLab i przewiń w dół do sekcji „Wersje”. Możesz wybrać link do magnesu torrent lub pobrać z mega.nz. Mega użytkownicy mogą kliknąć plik prawym przyciskiem myszy, wybrać pobierz, a następnie standardowe pobranie.
Po zakończeniu pobierania możesz dwukrotnie kliknąć plik .exe (archiwum samorozpakowujące się) lub użyć swojego ulubionego programu zip do rozpakowania. Microsoft Defender może temu zapobiec jako nierozpoznana aplikacja. To nie jest wirus; jest to plik ZIP. Kliknij „Więcej informacji”, a następnie „Uruchom mimo to”. Nie ma konfiguracji dla DeepFaceLab. Po rozpakowaniu plików instalacja jest zakończona.
wymagania systemowe
Sztuczna inteligencja zamiana twarzy na wideo – AI zastępująca twarz
Chociaż istnieje niewiele oficjalnych wymagań systemowych poza tymi wymienionymi powyżej, oto kilka ogólnych zaleceń, które mogą być pomocne:
| Część | Rekomendacje |
|---|---|
| System operacyjny | Windows 10/11 lub Linux. Angielski układ klawiatury. |
| GPU | Wysokiej klasy procesor graficzny NVIDIA z dużą ilością pamięci VRAM. |
| procesor | Co najmniej 4-rdzeniowy procesor. |
| Baran | Co najmniej 32 GB. Zależy od innego sprzętu, rozmiaru pliku stronicowania i rozmiaru projektu. |
| Składowanie | Pamięć SSD na oprogramowanie i pliki projektów. |
| Chłodzenie | Aktywne chłodzenie w pełnym wymiarze godzin z nieograniczonym przepływem powietrza. |
| Moc | Zapewnij wystarczającą moc do pokrycia szczytowego obciążenia systemu plus 30%. Używaj zasilania prądem zmiennym, a nie baterii. Wyłącz tryb ekonomiczny, uśpienie systemu itp. |
Wymagania systemowe DeepFaceLab 2.0
Sztuczna inteligencja zamiana twarzy
Optymalizacja systemu
| Włącz przyspieszane sprzętowo planowanie GPU | Polecany przez dewelopera. |
| Zwiększ rozmiar pliku stronicowania | Pomaga zmniejszyć awarie związane z brakiem pamięci (OOM). |
| Wyłącz animacje i efekty systemu Windows | Zmniejsza ilość zarezerwowanej pamięci VRAM systemu Windows. Uwaga: może zostać przywrócone do ustawień domyślnych przez usługę Windows Update. |
| NVIDIA NVLink dla wielu GP U | Użytkownicy wielu procesorów graficznych zgłaszają znaczny wzrost wydajności. |
Pliki i foldery wsadowe
Sztuczna inteligencja zamiana twarzy – Algorytmy AI robią zamiany twarzy
Otwórz folder, w którym rozpakowałeś DeepFaceLab. To są wszystkie pliki i foldery wymagane do wykonania deepfake’a, w tym kod DeepFaceLab, dodatkowe pakiety i oprogramowanie, folder obszaru roboczego i niektóre przykładowe dane wideo.
Pliki wsadowe w głównym folderze umożliwiają interakcję z oprogramowaniem. Są one ponumerowane w ogólnej kolejności, której należy przestrzegać, i mają nazwy opisujące ich cel. Możesz myśleć o nich jako o indywidualnych narzędziach, których będziesz używać w całym procesie deepfake. Same te pliki niewiele zdziałają. Raczej wywołują inne skrypty DFL i przekazują im argumenty, które z kolei inicjują rzeczywiste procesy deepfake.
Folder _internal zawiera kod DeepFaceLab oraz dodatkowe oprogramowanie i wymagane biblioteki, takie jak CUDA, Python i FFMpeg. Tutaj możesz zmodyfikować kod lub zainstalować rozwidlenie repozytorium DFL.

Pliki wsadowe i foldery DeepFaceLab 2.0
Wiki DeepFaceLab zawiera skróconą instrukcję i notatki na temat wszystkich plików wsadowych.
Przegląd obszaru roboczego
Sztuczna inteligencja zamiana twarzy – Zamiana twarzy AI
Folder obszaru roboczego to miejsce, w którym będą przechowywane wszystkie dane i pliki deepfake. Wewnątrz folderu obszaru roboczego znajdują się jeszcze 3 foldery, w których będą przechowywane obrazy i pliki modeli. Te dwa pliki wideo obejmują
data_src (źródłowe wideo) i data_dst (docelowe wideo).
Data_src to źródłowy zestaw twarzy, który chcesz zaimplementować w swoim filmie. Data_dst to docelowy film (oryginalny klip), w którym chcesz umieścić swoją głęboko fałszywą twarz. Pliki te można zastąpić wieloma popularnymi typami plików wideo, używając nazw plików data_src.* i data_dst.*.
Sztuczna inteligencja zamiana twarzy – face swap
Wspomniane powyżej skrypty wsadowe DeepFaceLab będą oczekiwać znalezienia plików w tych katalogach. Katalogi, które nie istnieją, są zwykle tworzone przez program w razie potrzeby. Ogólnie rzecz biorąc, nie należy próbować przenosić ani zmieniać nazw folderów. Na przykład możesz utworzyć kopię zapasową folderu „/aligned” jako „/aligned-copy”. Możesz dowolnie przenosić lub zmieniać nazwę folderu „/aligned-copy”; zostanie zignorowany przez oprogramowanie. Jeśli jednak przeniesiesz lub zmienisz nazwę folderu „/aligned”, nie zostanie on znaleziony przez DeepFaceLab, a Twój deepfake zakończy się niepowodzeniem. Należy również unikać używania nazw folderów, które mogą być „zarezerwowane” przez DeepFaceLab, chyba że zawierają oczekiwane pliki.
| Teczka | Opis |
|---|---|
| /workspace | Kontener plików wideo data_dst.* i data_src.*. |
| -/data_dst | Kontener na dane miejsca docelowego. Umieść docelową sekwencję obrazów w tym folderze. |
| -/aligned | Kontener dla docelowych obrazów zestawu twarzy. Umieść wyrównane obrazy zestawu twarzy w tym folderze. |
| –/aligned_debug | Kontener dla wygenerowanych docelowych obrazów debugowania. |
| -/data_src | Kontener na dane źródłowe. Umieść sekwencję obrazów źródłowych w tym folderze. |
| -/aligned | Kontener na źródłowe obrazy zestawów twarzy. Umieść wyrównane obrazy zestawu twarzy w tym folderze. |
| –/aligned_debug | Kontener dla wygenerowanych źródłowych obrazów debugowania. |
| -/model | Kontener na dane modelu. Umieść pliki modelu w tym folderze, w tym pliki modelu XSeg. |
| –/*_automatyczne kopie zapasowe | Kontener automatycznych kopii zapasowych wygenerowanego pliku modelu. |
Foldery obszaru roboczego DeepFaceLab 2.0
Krok 1: Wyczyść obszar roboczy i zaimportuj dane
Cel: Zdefiniowanie obszaru roboczego projektu.
Opcjonalnie: 1) wyczyść plik workspace.bat
Usuwa wszystkie dane w podkatalogach obszaru roboczego i odbudowuje strukturę folderów. Zachowuje pliki wideo data_src.* i data_dst.*. Używaj ostrożnie.
Importowanie danych
Umieść źródłowy i docelowy plik wideo w folderze obszaru roboczego, używając nazw plików data_src.* i data_dst.*
Podstawowy deepfake zaczyna się od 2 filmów. Możesz zaimportować własne dane lub pobrane pliki do wskazanych poniżej katalogów.
| Dane | Lokalizacja |
|---|---|
| Wideo | Umieść źródłowy i docelowy plik wideo w folderze obszaru roboczego Użyj nazw plików data_src.* i data_dst.* |
Zdjęcia Sekwencja obrazów | Umieść obrazy źródłowe w /data_src Umieść obrazy docelowe w /data_dst Przejdź do kroku 4 lub kroku 5 |
| Zestaw twarzy | Umieść zestaw twarzy wyrównany do źródła w /data_src/aligned Umieść zestaw twarzy wyrównany do miejsca docelowego w /data_dst/aligned Przejdź do kroku 4.2 lub kroku 5.2 |
| Model XSeg Model | Umieść pliki modelu w /model |
| Wstępny zestaw twarzy | Umieść faceset.pak w _internal/pretrain_faces |
| Ogólny model XSeg | Umieść wstępnie przeszkolone ogólne pliki modelu XSeg w _internal/model_generic_xseg |
DeepFaceLab 2.0 Importowanie zestawów danych
Krok 2: Wyodrębnij obrazy klatek źródłowych z wideo
Cel: Dostarczenie DeepFaceLab danych obrazu źródłowego do wyodrębnienia zestawu twarzy.
Plik wideo należy najpierw przekonwertować na sekwencję obrazów. Obrazy te będą celem wyodrębniania źródłowego zestawu twarzy i można je usunąć po wykonaniu kroku 4.2, gdy zestaw źródłowy zostanie ukończony. Jeśli zaimportowałeś własne zdjęcia źródłowe lub obrazy, możesz przejść do kroku 3.
Uruchom: 2) wyodrębnij obrazy z pliku wideo data_src.bat
- Enter FPS: Ustawia liczbę klatek na sekundę (częstotliwość) ekstrakcji.
Ogranicz liczbę klatek wyodrębnionych z długich klipów i tych z małą różnorodnością. Jeśli Twój klip ma wiele różnych lub unikalnych klatek, możesz wyodrębnić wszystkie klatki, wprowadzając „0”.
Przykład: wyodrębnianie 15 kl./s z filmu, który wynosi 30 kl./s = 15/30 = 1/2 klatek jest wyodrębnianych.
[Podpowiedź: ile klatek z każdej sekundy filmu zostanie wyodrębnionych. 0 – pełne fps.] - Format obrazu wyjściowego ( png / jpg ): Wybierz skompresowany JPEG lub nieskompresowany PNG.
Wybierz png, aby uzyskać najlepszą jakość obrazu.
[Podpowiedź: png jest bezstratny, ale ekstrakcja jest 10 razy wolniejsza w przypadku HDD i wymaga 10 razy więcej miejsca na dysku niż jpg.]
Plik wideo zostanie przetworzony i dla każdej klatki zostanie utworzony plik .png lub .jpg. Pliki będą wyliczane począwszy od '00001.*’ (np. 00001.png). Naciśnij dowolny klawisz lub po prostu zamknij okno.

Próbka: Wyodrębnione obrazy DeepFaceLab 2.0
Krok 3: Wyodrębnij obrazy klatek docelowych z wideo
Cel: Dostarczenie DeepFaceLab docelowych danych obrazu do wyodrębnienia zestawu twarzy.
Te obrazy będą celem wyodrębniania docelowego zestawu twarzy. Ponieważ docelowe wideo będzie wymagało wszystkich klatek, nie ma danych wejściowych fps do wyodrębnienia; wszystkie ramki zostaną wyodrębnione. Obrazy docelowe zostaną użyte do połączenia ostatecznych klatek obrazu i wideo, dlatego należy je zachować na czas trwania projektu. Jeśli zaimportowałeś własne zdjęcia miejsca docelowego lub sekwencję obrazów, możesz przejść do kroku 4.
Uruchom: 3) wyodrębnij obrazy z wideo data_dst FULL FPS.bat
- Format obrazu wyjściowego ( png / jpg ): Wybierz skompresowany JPEG lub nieskompresowany PNG.
Wybierz png, aby uzyskać najlepszą jakość obrazu.
[Podpowiedź: png jest bezstratny, ale ekstrakcja jest 10 razy wolniejsza w przypadku HDD i wymaga 10 razy więcej miejsca na dysku niż jpg.]
Plik wideo zostanie przetworzony i dla każdej klatki zostanie utworzony plik .png lub .jpg. Pliki będą wyliczane począwszy od „00001”. Naciśnij dowolny klawisz lub po prostu zamknij okno.
Opcjonalnie: 3) wytnij wideo (upuść wideo na mnie).bat
Przed wyodrębnieniem możesz przyciąć klip wideo. Upuść plik wideo bezpośrednio na ten plik wsadowy, aby otworzyć okno dialogowe opcji.
- Od czasu: kod czasowy dla punktu początkowego edycji.
- Do czasu: Kod czasowy dla punktu końcowego edycji.
- Określ identyfikator ścieżki dźwiękowej: Wybierz ścieżkę dźwiękową, której chcesz użyć.
Sprawdź plik, aby zobaczyć dostępne ścieżki audio. - Szybkość transmisji pliku wyjściowego w MB/s: Ustaw szybkość transmisji pliku wyjściowego.
Nowy plik wideo pojawi się w tym samym katalogu co oryginalny plik z dodanym do nazwy plikiem „_cut”. Zalecamy umieszczenie pliku wideo w obszarze roboczym przed cięciem, aby pliki się nie zgubiły.
Opcjonalnie: 3.opcjonalnie) denoise data_dst images.bat
Odszumiaj obrazy docelowe po ekstrakcji.
- Denoise factor ( 1 – 20 ): Ustaw wartość (siłę) algorytmu denoise.

Próbka: porównanie DeepFaceLab 2.0 Denoise
Krok 4: Wyodrębnij źródłowy zestaw twarzy
Cel: Zapewnienie firmie DeepFaceLab obrazów i metadanych zestawów twarzy dopasowanych do źródła.
Teraz w rezultacie przetworzysz obrazy i wyodrębnisz twarze do wykorzystania w deepfake. DeepFaceLab wykryje twarze na obrazach, ponadto określi punkty orientacyjne twarzy, wygeneruje domyślną maskę, wyrówna twarze i wygeneruje plik dla każdej wykrytej twarzy, w tym osadzone metadane. Poniższy obraz przedstawia układ punktów orientacyjnych twarzy.

Diagram: Punkty orientacyjne wyrównania twarzy w DeepFaceLab 2.0
Nazwy plików będą oparte na oryginalnej (rodzicielskiej) nazwie pliku obrazu. Ponieważ obraz może zawierać więcej niż jedną twarz, każda twarz otrzymuje numer indeksu (zaczynający się od 0), wskazany przez sufiks w nazwie każdego pliku (np. 12345_0.jpg). Na poniższym obrazku widać punkty orientacyjne twarzy (zielone), domyślną maskę (szarą), ramkę wykrywania twarzy (niebieską), ramkę wyrównania obrazu (czerwona), wskaźnik kierunku w górę (czerwony trójkąt) oraz próbkę wyniku nazwy plików. Jak widać, wyodrębniony zestaw twarzy jest przycięty i wyrównany do czerwonej ramki ograniczającej.

Próbka: DeepFaceLab 2.0 Source Faceset Indexs
Jeśli zaimportowałeś własny zestaw twarzy źródłowych, możesz przejść do kroku 5.
Istnieją 2 sposoby wyodrębnienia źródłowego zestawu twarzy: tryb automatyczny lub ręczny. Automatyczny ekstraktor przetworzy wszystkie pliki bez przerwy, podczas gdy ręczny ekstraktor pozwala ustawić wyrównanie twarzy dla każdej klatki za pomocą klawiatury i myszy. Tryb ręczny nie jest konieczny w przypadku większości deepfake’ów, ale można go użyć do wyrównania szczególnie trudnych twarzy, takich jak ekstremalne kąty, obrazy z ciężkimi efektami wizualnymi, animowane postacie, a nawet zwierzęta.
Typy twarzy – Sztuczna inteligencja zamiana twarzy na video
Typ twarzy to pierwsza krytyczna decyzja, którą musisz podjąć w procesie deepfake, ponieważ określa ona maksymalny obszar twarzy, który można wytrenować. Większy typ twarzy, który obejmuje więcej twarzy i głowy, zapewni lepszy deepfake, jednak będzie wymagał więcej zasobów systemowych, dłuższego czasu szkolenia, dodatkowego maskowania i przetwarzania końcowego. Ponieważ typ twarzy musi uwzględniać różne kąty, niektóre wyodrębnione obrazy mogą zostać przycięte mocniej, podczas gdy inne pozostawią więcej miejsca wokół twarzy. Większy typ twarzy może również służyć do trenowania zestawu modeli do mniejszego typu twarzy. Wielu twórców deepfake’ów wybiera typ całej twarzy (wf), aby uzyskać równowagę między szybkością a podobieństwem.
| Typ twarzy | Opis |
|---|---|
| głowa | Głowa. Obejmuje całą głowę i włosy do szyi. Wykorzystuje punkty orientacyjne 3D. |
| wf | Cała twarz. Zakrywa czubek głowy do podbródka. |
| F | Pełna twarz. Zakrywa czoło do brody. |
| mf | Środkowa twarz (starsza wersja). Obejmuje brwi do brody. |
| hf | Pół twarzy (starszy). Zakrywa oczy do ust. |
Typy twarzy DeepFaceLab 2.0

Diagram: Porównanie typów twarzy w DeepFaceLab 2.0
Na powyższym obrazku widać 3 najczęstsze typy twarzy i oryginalne zdjęcie ramki. Zwróć uwagę, że podczas gdy typ Głowa obejmuje największy obszar, twarz wydaje się najmniejsza na wyrównanych obrazach po lewej stronie. Będziesz musiał dostosować rozmiar obrazu (rozdzielczość) do typu twarzy i rozdzielczości oryginalnego materiału filmowego. Możesz także zmierzyć lub przybliżyć rozmiar twarzy w swoich ramkach, aby określić odpowiedni rozmiar obrazu. Typ twarzy będzie również musiał zostać wprowadzony podczas maskowania XSeg i, co najważniejsze, podczas uczenia modelu deepfake. Typ twarzy będzie miał ogromny wpływ na szybkość treningu i jakość rezultatu.
Uruchom: 4) data_src faceset extract.bat (automatycznie)
- Które indeksy GPU wybrać?: Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić wyodrębnianie.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU. - Typ twarzy (f / wf / head ): Wybierz typ twarzy do ekstrakcji.
[Podpowiedź: cała twarz / cała twarz / głowa. „Cała twarz” obejmuje całą powierzchnię twarzy, w tym czoło. „head” obejmuje całą głowę, ale wymaga XSeg dla src i dst faceset.] - Maksymalna liczba twarzy z obrazu: Wybierz maksymalną liczbę twarzy do wyodrębnienia z każdej klatki.
[Podpowiedź: jeśli wyodrębniasz faceset src, który ma ramki z dużą liczbą twarzy, zaleca się ustawienie maksymalnej liczby twarzy na 3, aby przyspieszyć ekstrakcję. 0 – bez ograniczeń] - Rozmiar obrazu ( 256 – 2048 ): Wybierz rozmiar (rozdzielczość) wyodrębnionych plików obrazów Faceset.
[Etykietka: Rozmiar obrazu wyjściowego. Im większy rozmiar obrazu, tym gorzej działa wzmacniacz twarzy. Użyj wartości wyższej niż 512 tylko wtedy, gdy obraz źródłowy jest wystarczająco ostry, a twarz nie wymaga uwydatnienia.] - Jakość Jpeg ( 1 – 100 ): Wybierz jakość (kompresję) wyodrębnionych plików obrazów Faceset.
[Podpowiedź: jakość JPEG. Im wyższa jakość JPEG, tym większy rozmiar pliku wyjściowego.] - Zapisać obrazy debugowania do wyrównane_debug? ( y/n ): Wybierz, czy chcesz zapisywać obrazy debugowania.
Po kilku minutach ekstrakcja kończąc się i wyświetli raport na temat liczby znalezionych obrazów i wykrytych twarzy. Pliki obrazów źródłowych zestawów twarzy zostaną utworzone w folderze data_src/aligned.
Opcjonalnie: 4) data_src wyciąg twarzy MANUAL.bat
Ręczny ekstraktor facesetów źródłowych ma te same opcje co 4) data_src faceset extract.bat . Otwiera interfejs do ręcznego ustawiania punktów orientacyjnych wyrównania zestawu twarzy na obrazach. Tryb ręczny umożliwia wybór tylko jednej twarzy na klatkę.

Próbka: Wyciąg z podręcznika DeepFaceLab 2.0
| Wejście | Opis |
|---|---|
| Kliknięcie myszą | wybór blokady/odblokowania |
| Kliknięcie myszą | ręczny prostokąt twarzy |
| Kółko w myszce | zmienić rozmiar prostokąta |
| Wchodzić | potwierdź wybór |
| Przestrzeń | pomiń ramkę |
| , (przecinek) | poprzednia klatka |
| . (okres) | następna ramka |
| Q | pomiń pozostałe klatki |
| A | celność włączona/wyłączona (więcej fps) |
| H | ukryj tę pomoc |
DeepFaceLab 2.0 Ręczne wyodrębnianie danych wejściowych z klawiatury
Krok 4.1: Zobacz źródłowy wynik Faceset
Po ekstrakcji możesz wyświetlić źródłowy wynik zestawu twarzy za pomocą dołączonej przeglądarki obrazów VNView.
Uruchom: 4.1) data_src zobacz wyrównany wynik.bat
Źródłowy zestaw twarzy zostanie otwarty za pomocą dołączonej przeglądarki obrazów XNView. Pliki te można również znaleźć w folderze data_src/aligned. Zauważysz, że obrazy są ponumerowane w kolejności wraz z sufiksem zawierającym podkreślenie i liczbę. DeepFaceLab nazywa każdy plik na podstawie numeru oryginalnego zdjęcia i indeksu twarzy na zdjęciu, oczywiście NIE zmieniaj tutaj nazw plików. Pierwsza twarz, oznaczona sufiksem _0, jest zwykle największą twarzą w obrazie ramki nadrzędnej.
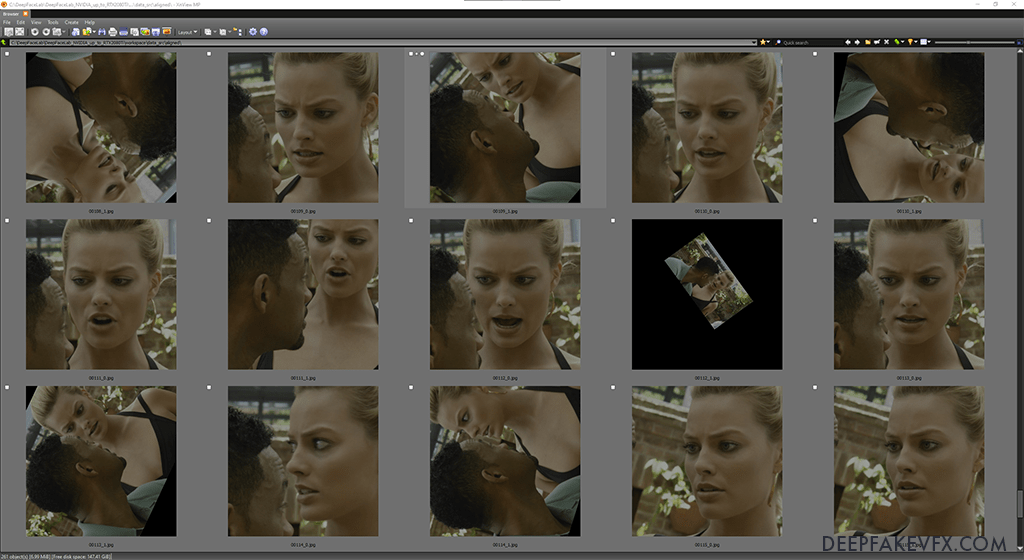
Przykład: przeglądarka obrazów DeepFaceLab 2.0 XNView
Usuń niechciane twarze według indeksu
Jeśli nie ograniczyłeś maksymalnej liczby twarzy na obraz, ekstraktor może generować liczne niepożądane ekstrakcje twarzy i fałszywe wykrycia.

Przykład: DeepFaceLab 2.0 Source Faceset Wykrywanie duplikatów
Próbki źródłowe Faceset Raw Extraction:

Próbka: DeepFaceLab 2.0 wyodrębniony zestaw twarzy przed czyszczeniem
Krok 4.2: Sortowanie i czyszczenie zestawu twarzy źródłowych
Cel: Wybieranie źródłowych danych wejściowych.
Ekstraktor twarzy wyeksportuje wiele twarzy z oryginalnych obrazów i może również zawierać fałszywe wykrycia, źle wyrównane twarze i zduplikowane obrazy. Celem czyszczenia źródłowego zestawu twarzy jest utworzenie zestawu twarzy obiektu, który jest dokładnie wyrównany, z dużą różnorodnością i kilkoma duplikatami. Ponieważ prawdopodobnie będziesz mieć mnóstwo obrazów źródłowych, możesz usunąć wszystkie twarze, co do których nie masz pewności. Należy również przyciąć źródłowy zestaw powierzchni, aby pasował do docelowych kątów, wyrażeń i kolorów. Wróć do tej sekcji po wyodrębnieniu docelowego zestawu twarzy.
Źródłowy zestaw twarzy po oczyszczeniu i przycięciu:

Przykład: DeepFaceLab 2.0 wyodrębniony zestaw twarzy po oczyszczeniu
Uruchom: 4.2) data_src sort.bat
Do wyboru jest wiele różnych metod sortowania. Sortowanie według podobieństwa histogramu grupuje podobne obrazy, pomagając masowo usuwać niechciane twarze i bardzo podobne obrazy. Sortowanie według wysokości i sortowanie według odchylenia pomoże ci wybrać złe wyrównania. Sortowanie według rozmycia pozwala usunąć obrazy o niskiej jakości.
Zamiana twarzy oparta na sztucznej inteligencji
Te metody sortowania zmienią nazwy plików w nowej kolejności. Uruchomienie pliku „4.2) data_src util recovery original filename” przywróci oryginalne nazwy i kolejność plików. Jedynymi wyjątkami są szybsze sortowanie według najlepszych twarzy i najlepszych twarzy. Te dwie metody poproszą Cię o wprowadzenie żądanej liczby obrazów, z których wybierze różne twarze o różnych właściwościach. Pozostałe obrazy zostaną przeniesione do folderu „aligned_trash”. Najlepsze sortowanie twarzy nie jest bardzo dokładne, więc nie polegaj wyłącznie na nim podczas tworzenia zestawu twarzy.
| Metoda sortowania | Opis |
|---|---|
| [0] rozmycie | Sortuj według rozmycia obrazu na podstawie kontrastu. |
| [1] rozmycie ruchu | Sortuj według rozmycia ruchu. |
| [2] twarz w kierunku odchylenia | Sortuj według odchylenia (w poziomie / od lewej do prawej). |
| [3] kierunek pochylenia twarzy | Sortuj według wysokości (w pionie / od góry do dołu). |
| [4] rozmiar prostokąta twarzy w obrazie źródłowym | Sortuj według rozmiaru twarzy w oryginalnym obrazie klatki wideo (malejąco). |
| [5] podobieństwo histogramu | Sortuj według podobieństwa histogramu (malejąco). |
| [6] odmienność histogramu | Sortuj według podobieństwa histogramu (rosnąco). |
| [7] jasność | Sortuj według jasności obrazu. |
| [8] odcień | Sortuj według odcienia obrazu. |
| [9] liczba czarnych pikseli | Sortuj według ilości czarnych pikseli w obrazie (rosnąco). |
| [10] oryginalna nazwa pliku | Sortuj według kolejności oryginalnej nazwy pliku. Nie przywraca oryginalnej nazwy pliku. |
| [11] jedna twarz na zdjęciu | Sortuj według liczby twarzy w oryginalnym obrazie klatki wideo (rosnąco). |
| [12] bezwzględna różnica pikseli | Sortuj według bezwzględnej różnicy. |
| [13] najlepsze twarze | Sortuj według wielu metod (z rozmyciem) i usuwaj podobne twarze. Wybierz docelową liczbę obrazów twarzy do zachowania. Odrzucone twarze przeniesiono do data_src/aligned_trash. |
| [14] najlepsze twarze szybciej | Sortuj według wielu metod (z rozmiarem prostokąta twarzy) i usuwaj podobne twarze. Wybierz docelową liczbę obrazów twarzy do zachowania. Odrzucone twarze przeniesiono do data_src/aligned_trash. |
Metody sortowania DeepFaceLab 2.0

Przykład: Metody sortowania DeepFaceLab 2.0
Data_src Narzędzia
Istnieje kilka narzędzi, które pomogą ci w manipulowaniu obrazem źródłowym.
| Data_src Narzędzie | Opis |
|---|---|
| 4.2) data_src util dodawanie punktów orientacyjnych debugowanie images.bat | Dodaj obrazy debugowania punktów orientacyjnych twarzy. Duplikuje obrazy zestawów twarzy w data_src/aligned. Dodaje widoczne punkty orientacyjne do obrazów. Dołącza „_debug” do nazwy pliku. Uwaga: Usuń obrazy debugowania z zestawu twarzy przed uczeniem. |
| 4.2) data_src util Faceset Enhance.bat | Ulepsz zestaw twarzy źródłowych poprzez upscale. Ulepszone obrazy zostaną utworzone w data_src/aligned_enhanced. Zostaniesz zapytany, czy chcesz zastąpić (nadpisać) oryginalne obrazy. |
| 4.2) data_src util Faceset metadata restore.bat | Przywróć źródłowe metadane zestawu twarzy z pliku meta.dat. |
| 4.2) data_src util metadanych zestawu twarzy save.bat | Zapisz źródłowe metadane zestawu twarzy jako plik meta.dat. [Konsola: Teraz możesz edytować obrazy.!!! Zachowaj te same nazwy plików w folderze. Możesz zmienić rozmiar obrazów, proces przywracania spowoduje zmniejszenie rozmiaru z powrotem do oryginalnego rozmiaru. Następnie użyj przywracania metadanych.] |
| 4.2) data_src util faceset pack.bat | Spakuj zestaw twarzy źródła jako plik data_src/aligned/faceset.pak. Zostaniesz zapytany, czy chcesz usunąć oryginalne pliki. |
| 4.2) data_src util faceset resize.bat | Zmień rozmiar i zmień typ twarzy źródłowych obrazów faceset. [Uwaga: połowa twarzy / środkowa twarz / cała twarz / cała twarz / głowa / bez zmian] Obrazy o zmienionym rozmiarze zostaną utworzone w data_src/aligned_resized. Zostaniesz zapytany, czy chcesz zastąpić (nadpisać) oryginalne obrazy. |
| 4.2) data_src util faceset unpack.bat | Rozpakuj źródłowy plik data_src/aligned/faceset.pak. Faceset.pak zostanie usunięty. |
| 4.2) data_src util odzyskać oryginalną nazwę pliku.bat | Po sortowaniu zmień nazwy źródłowych plików zestawów twarzy na oryginalne nazwy plików. Nazwy plików Faceset są pobierane z oryginalnej nazwy pliku obrazu klatki wideo. |
Narzędzia źródłowe DeepFaceLab 2.0
Krok 5: Wyodrębnij docelowy zestaw twarzy
Cel: Zapewnienie firmie DeepFaceLab obrazów twarzy dostosowanych do miejsca docelowego.
Proces wyodrębniania docelowego zestawu twarzy jest podobny do procesu wyodrębniania zestawu twarzy źródłowego. Jeśli zaimportowałeś własny docelowy zestaw twarzy, możesz przejść do kroku 5.3.
Uruchom: 5) data_dst faceset extract.bat
- Które indeksy GPU wybrać?: Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić wyodrębnianie.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU. - Typ twarzy (f / wf / head ): Wybierz typ twarzy do ekstrakcji.
[Podpowiedź: cała twarz / cała twarz / głowa. „Cała twarz” obejmuje całą powierzchnię twarzy, w tym czoło. „head” obejmuje całą głowę, ale wymaga XSeg dla src i dst faceset.] - Rozmiar obrazu ( 256 – 2048 ): Wybierz rozmiar (rozdzielczość) wyodrębnionych plików obrazów Faceset.
[Etykietka: Rozmiar obrazu wyjściowego. Im większy rozmiar obrazu, tym gorzej działa wzmacniacz twarzy. Użyj wartości wyższej niż 512 tylko wtedy, gdy obraz źródłowy jest wystarczająco ostry, a twarz nie wymaga uwydatnienia.] - Jakość Jpeg ( 1 – 100 ): Wybierz jakość (kompresję) wyodrębnionych plików obrazów Faceset.
[Podpowiedź: jakość JPEG. Im wyższa jakość JPEG, tym większy rozmiar pliku wyjściowego.]
Po kilku minutach ekstrakcja zakończy się i wyświetli raport na temat liczby znalezionych obrazów i wykrytych twarzy. Docelowe pliki obrazów zestawów twarzy zostaną utworzone w folderze data_src/aligned. Obrazy debugowania będą również generowane w folderze data_dst/aligned_debug.
Opcjonalnie: 5) data_dst ekstrakt zestawu twarzy MANUAL.bat
Ręczny ekstraktor zestawu twarzy miejsca docelowego ma te same opcje, co 5) data_dst ekstrakt zestawu twarzy.bat . Otwiera interfejs do ręcznego ustawiania punktów orientacyjnych wyrównania zestawu twarzy na obrazach. Tryb ręczny umożliwia wybór tylko jednej twarzy na klatkę.
Opcjonalnie: 5) wyciąg danych data_dst faceset + ręczny fix.bat
Docelowy ekstraktor zestawu twarzy z ręczną poprawką ma te same opcje, co 5) data_dst ekstrakt zestawu twarzy.bat . Automatyczny ekstraktor docelowych zestawów twarzy z opcją ręcznego wyznaczania punktów orientacyjnych dla niewykrytych ramek. Po automatycznym wyodrębnieniu otworzy się interfejs umożliwiający ręczne ustawienie punktów orientacyjnych wyrównania zestawu twarzy na klatkach wideo bez wykrytych twarzy. Tryb ręczny umożliwia wybór jednej twarzy na klatkę.
Ręczne ponowne wyodrębnianie twarzy
Możesz ręcznie ponownie wyodrębnić słabo wyrównane lub niewykryte twarze. Możesz chcieć wrócić do tego kroku po usunięciu niechcianych twarzy.
Najpierw otwórz folder data_dst/aligned_debug, uruchamiając 5.1) data_dst viewaligned_debug Results.bat . Usuń wszystkie obrazy, które zawierają słabo wyrównane lub niewykryte twarze, które chcesz uwzględnić w docelowym zestawie twarzy. Następnie ręcznie ponownie wyodrębnisz twarze tylko z usuniętych klatek. Ponieważ w trybie ręcznym można wybrać tylko jedną twarz, to zdjęcie otrzyma indeks _0 i zastąpi aktualnie wyrównany obraz dla tej ramki i indeksu twarzy. Wyrównane obrazy dla tej ramki, które mają inne indeksy, pozostaną. Chociaż nie jest to wymagane, pomocne może być również usunięcie odpowiednich wyrównanych obrazów podczas usuwania obrazów debugowania.

Przykład: DeepFaceLab 2.0 Data_dst Wyświetl wyrównane debugowanie
Opcjonalnie: 5) data_dst faceset MANUAL RE-EXTRACT USUNIĘTO ALIGNED_DEBUG.bat
Otwiera interfejs do ręcznego ustawiania punktów orientacyjnych wyrównania zestawu twarzy na klatkach wideo odpowiadających tylko usuniętym obrazom debugowania.
- Które indeksy GPU wybrać?: Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić wyodrębnianie.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU. - Rozmiar obrazu ( 256 – 2048 ): Wybierz rozmiar (rozdzielczość) wyodrębnionych plików obrazów Faceset.
[Etykietka: Rozmiar obrazu wyjściowego. Im większy rozmiar obrazu, tym gorzej działa wzmacniacz twarzy. Użyj wartości wyższej niż 512 tylko wtedy, gdy obraz źródłowy jest wystarczająco ostry, a twarz nie wymaga uwydatnienia.] - Jakość Jpeg ( 1 – 100 ): Wybierz jakość (kompresję) wyodrębnionych plików obrazów Faceset.
[Podpowiedź: jakość JPEG. Im wyższa jakość JPEG, tym większy rozmiar pliku wyjściowego.]
Interfejs i proces są takie same jak w 4) podręczniku wyodrębniania zestawu danych data_src . Nie będzie można zmienić typu twarzy. Konsola zarejestruje liczbę znalezionych obrazów i wykrytych twarzy.
Sztuczna inteligencja zamiana twarzy
Krok 5.1: Wyświetl wynik zestawu docelowego
Po wyodrębnieniu możesz wyświetlić docelowy zestaw twarzy.
Uruchom: 5.1) data_dst zobacz wyrównane wyniki.bat
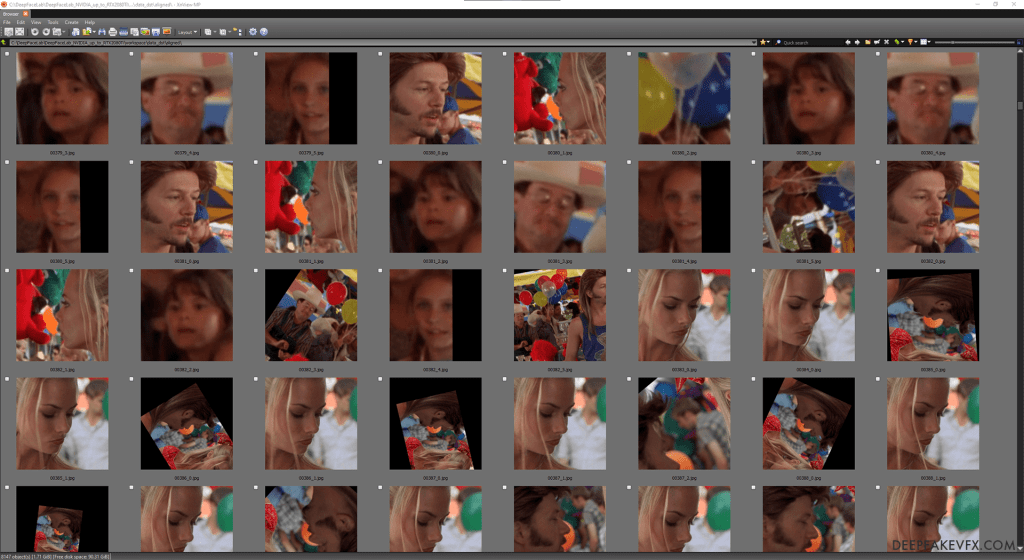
Przykład: DeepFaceLab 2.0 Destination Faceset
Usuń niechciane twarze według indeksu
Aby uzyskać instrukcje , zapoznaj się z metodą wyszukiwania indeksu w Kroku 4.1: Zobacz wynik Faceset źródła . Postaraj się zachować jak najwięcej docelowych obrazów zestawu twarzy. Zacznij od usunięcia twarzy innych osób i fałszywych detekcji. Później możesz odwołać się do obrazów debugowania, aby usunąć i naprawić złe wyrównania.
Ponownie, pamiętaj o możliwych zduplikowanych i źle umieszczonych ekstrakcjach twarzy. Ponieważ chcesz zachować jak najwięcej twarzy docelowych, musisz zadbać o to, aby określić, które twarze zachować, a które usunąć. Na poniższym obrazku widać, że wyodrębniono 2 podobne twarze. Podczas gdy ramka ograniczająca twarz (niebieska) znalazła 2 różne twarze, wyrównania obiektów (zielone) są zasłonięte, co spowodowało, że ramka ograniczająca obrazu (czerwona) była skierowana na niewłaściwą twarz. Użyj obrazów debugowania, aby określić, która twarz jest idealna.

Przykład: DeepFaceLab 2.0 Wykrywanie duplikatów twarzy
Opcjonalnie: 5.1) data_dst widokalign_debug Results.bat
Otwiera docelowe obrazy wyrównane_debug w XNView. Użyj tej przeglądarki obrazów, aby znaleźć odpowiednie obrazy zestawu twarzy ze słabym wyrównaniem.
Przed uruchomieniem 5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG użyj tej przeglądarki do usunięcia obrazów debugowania zawierających słabo wyrównane twarze.
Krok 5.2: Sortowanie docelowego zestawu twarzy, czyszczenie i ponowna ekstrakcja
Cel: Wybieranie danych wejściowych miejsca docelowego.
Uruchom: 5.2) data_dst sort.bat
Zapoznaj się z metodami sortowania w Kroku 4.2: Sortowanie i czyszczenie zestawu twarzy źródłowych, aby uzyskać podstawowe instrukcje.
W docelowym zestawie twarzy chcesz zachować jak najwięcej obrazów twarzy, ponieważ usunięte twarze nie pojawią się w końcowym deepfake’u.
Narzędzia Data_dst
Istnieje kilka narzędzi, które pomogą Ci w manipulowaniu obrazem miejsca docelowego.
| data_dst narzędzie | Opis |
|---|---|
| 4.2) data_dst util faceset pack.bat | Spakuj docelowy zestaw twarzy jako plik data_dst/aligned/faceset.pak. Usunąć oryginalne pliki? ( t / n ) : Wybierz usunięcie oryginalnych plików po spakowaniu. |
| 4.2) data_dst util faceset resize.bat | Zmień rozmiar i zmień typ twarzy docelowych obrazów faceset. Obrazy o zmienionym rozmiarze zostaną utworzone w data_dst/aligned_resized. Nowy rozmiar obrazu ( 128-2048 ): Wybierz nowy rozmiar obrazu (rozdzielczość) Faceset. Zmień typ twarzy (h / mf / f / wf / head / same ): Wybierz, aby zmienić typ twarzy. [Uwaga: połowa twarzy / środkowa twarz / cała twarz / cała twarz / głowa / bez zmian] Scal źródło_danych/aligned_resized do data_src/aligned ?: Wybierz, aby zastąpić (nadpisać) oryginalne obrazy zestawu twarzy obrazami o zmienionym rozmiarze. |
| 4.2) data_dst util faceset unpack.bat | Rozpakuj docelowy plik data_dst/aligned/faceset.pak. Faceset.pak zostanie usunięty. |
| 4.2) data_dst narzędzie do odzyskiwania oryginalnej nazwy pliku.bat | Zmień nazwy docelowych plików zestawów twarzy na oryginalne nazwy plików po posortowaniu. Nazwy plików Faceset są pobierane z oryginalnej nazwy pliku obrazu klatki wideo. |
Narzędzia docelowe DeepFaceLab 2.0
Deepfake (technika wykorzystaniaa SI do manipulacji twarzami)
Krok 5.3: Etykietowanie maski XSeg i szkolenie z modelu XSeg
Cel: Zdefiniowanie obszaru maski zestawu twarzy do trenowania i scalania modeli.
Każda twarz będzie również zawierała domyślną maskę wygenerowaną podczas wyodrębniania. Tworzenie maski Xseg pozwala określić, które obszary twarzy będą trenowane, a które nie, oraz określa kształt maski do wykorzystania podczas łączenia. Użycie XSeg zapewni lepszą kompozycję i większe podobieństwo do źródłowego zestawu twarzy. Maskowanie XSeg pomoże również modelowi określić wymiary i cechy twarzy, co spowoduje bardziej realistyczny ruch oczu i ust. Podczas gdy maska domyślna może być przydatna w przypadku mniejszych typów twarzy, większe typy twarzy, takie jak cała twarz i głowa, wymagają niestandardowej maski XSeg, aby uzyskać najlepsze rezultaty. Maska Xseg pozwala również wykluczyć przeszkody, takie jak dłonie, włosy, okulary, kolczyki i tak dalej.
Narzędzia XSeg
Zanim zaczniesz korzystać z XSeg, przeczytaj tę tabelę z różnymi dostępnymi narzędziami.
| Narzędzie XSeg | Opis |
|---|---|
| 5.XSeg Generic) data_dst maska_całej_twarzy – Apply.bat | Zastosuj ogólną maskę pełnotwarzową XSeg do docelowego zestawu twarzy. |
| 5.XSeg Generic) data_src maska_całej_twarzy – Apply.bat | Zastosuj ogólną maskę pełnotwarzową XSeg do zestawu źródłowego. |
| 5.XSeg) data_dst maska – edit.bat | Edytuj docelowe etykiety masek XSeg. |
| 5.XSeg) data_dst maska – fetch.bat | Skopiuj obrazy zestawu docelowego z etykietą XSeg do data_dst/aligned_xseg. |
| 5.XSeg) data_dst maska – usuń.bat | Usuń etykiety maski XSeg z docelowych obrazów zestawów twarzy. |
| 5.XSeg) przeszkolona maska data_dst – apply.bat | Zastosuj przeszkoloną maskę XSeg do docelowego zestawu twarzy. |
| 5.XSeg) przeszkolona maska data_dst – remove.bat | Usuń przeszkoloną maskę XSeg z docelowego zestawu twarzy. |
| 5.XSeg) data_src maska – edit.bat | Edytuj źródłowe etykiety maski XSeg. |
| 5.XSeg) data_src mask – fetch.bat | Skopiuj źródłowe obrazy zestawów twarzy z etykietą XSeg do data_src/aligned_xseg. |
| 5.XSeg) data_src mask – usuń.bat | Usuń etykiety maski XSeg ze źródłowych obrazów zestawu twarzy. |
| 5.XSeg) przeszkolona maska data_src – apply.bat | Zastosuj przeszkoloną maskę XSeg do źródłowego zestawu twarzy. |
| 5.XSeg) przeszkolona maska data_src – remove.bat | Usuń przeszkoloną maskę XSeg ze źródłowego zestawu twarzy. |
| 5.XSeg) pociąg.nietoperz | Trenuj maski XSeg przy użyciu oznaczonych obrazów ze źródłowych i docelowych zestawów twarzy. |
Narzędzia DeepFaceLab 2.0 XSeg
Szybki start: generyczna wstępnie przeszkolona maska XSeg
Najszybszym sposobem na rozpoczęcie pracy z Xseg jest zastosowanie wstępnie wytrenowanej maski. DeepFaceLab zawiera ogólną maskę Xseg na całą twarz. Możesz także wstępnie wytrenować własną maskę lub pobrać wstępnie wytrenowaną maskę. Pliki masek ogólnych można znaleźć w folderze _internal/model_generic_xseg. Pamiętaj, że jest to maska typu Whole Face i może nie działać na innych typach twarzy.
Opcjonalnie: 5.XSeg Generic) data_dst Zastosuj maskę na całą twarz.bat
- Który indeks GPU wybrać?: Wybierz pojedynczy indeks GPU z listy, aby zastosować maskę XSeg.
Ogólna maska całej twarzy zostanie zastosowana do docelowego zestawu twarzy. Umieść wyszkolone ogólne pliki modelu XSeg w _internal/model_generic_xseg.
Opcjonalnie: 5.XSeg Generic) data_src cała maska na twarz Apply.bat
- Który indeks GPU wybrać?: Wybierz pojedynczy indeks GPU z listy, aby zastosować maskę XSeg.
Ogólna maska całej twarzy zostanie zastosowana do źródłowego zestawu twarzy. Ogólne wstępnie przeszkolone pliki modelu XSeg można znaleźć w _internal/model_generic_xseg.

Próbka: Zastosowano maskę DeepFaceLab 2.0 Generic XSeg
Jeśli zaczniesz lub będziesz kontynuować trening deepfake z zastosowaną maską ogólną, zauważysz, że zaczyna się tworzyć większy obszar maski. Przystosowanie się modelu do maski zajmie trochę czasu. Ta ogólna maska jest dobrym punktem wyjścia dla wielu projektów, jednak mogą wystąpić trudności z ekstremalnymi kątami i ciemnymi, rozmytymi lub mocno zasłoniętymi twarzami.
Etykietowanie masek XSeg
Aby utworzyć własną maskę Xseg, musisz najpierw oznaczyć niektóre twarze wielokątami maski. Następnie będziesz trenować i nakładać maskę na faceset.
Uruchom 5.XSeg) data_dst mask edit.bat
Zobaczysz ekran powitalny Xseg, a po załadowaniu obrazów będziesz mógł korzystać z interfejsu. Najpierw przejrzyjmy interfejs użytkownika XSeg.

Schemat: Interfejs maskujący DeepFaceLab 2.0 XSeg
Zacznij od oznaczenia niektórych łatwiejszych twarzy, które są wyraźne, w pełni odsłonięte i niezasłonięte. Wybierz wygodny punkt startowy i kierunek pracy wokół twarzy. Użyj lewego przycisku myszy, aby umieścić punkty wzdłuż krawędzi twarzy. Kółko myszy umożliwia powiększanie i pomniejszanie, ponowne wycentrowanie obrazu na kursorze. Użyj Ctrl + Z, aby cofnąć poprzednie punkty.
Po zakończeniu etykietowania powierzchni można uzupełnić wielokąt, klikając pierwszy punkt. Następnie można zmodyfikować wielokąt, przesuwając, dodając lub usuwając punkty. Podczas pracy nad zestawem twarzy staraj się zachować spójność kształtów maski, podążaj podobną ścieżką wokół szczęki i linii włosów na każdym zdjęciu. W przypadku mniejszych typów twarzy należy podążać za linią szczęki i czoła tuż nad brwiami. Podczas korzystania z zestawu twarzy typu Głowa będziesz musiał uwzględnić całą twarz, uszy, włosy i opcjonalnie część szyi. Cienkie lub poruszające się włosy będą trudne do sfałszowania, więc warto je udoskonalić w obróbce końcowej.
AI zastępująca twarz – Sztuczna inteligencja zamiana twarzy
Nie ma co skupiać się na wykonaniu precyzyjnej maski z setek punktów; wystarczy kilkadziesiąt. Zamiast tego poświęć swój czas na etykietowanie różnych twarzy w różnych zakresach odchylenia, wysokości i kolorów zestawu twarzy. Powinieneś również oznaczyć różne wyrazy twarzy, takie jak otwarte i zamknięte usta oraz oczy skierowane w różnych kierunkach. Możesz zamknąć edytor i użyć narzędzia do sortowania, aby zmienić kolejność obrazów, upewniając się, że masz dobre rozmieszczenie oznaczonych twarzy. Zwykle im więcej obrazów oznaczysz, tym lepsza będzie maska.
Uruchom 5.XSeg) data_src mask edit.bat
Zaleca się etykietowanie co najmniej kilkudziesięciu twarzy zarówno w źródłowym, jak i docelowym zestawie twarzy. W przypadku złożonego deepfake należy spodziewać się oznakowania 100 lub więcej twarzy.
Przeszkody i wykluczenia – Sztuczna inteligencja zamiana twarzy
Przeszkody przed twarzą można wykluczyć z obszaru maski. Pierwsza metoda to po prostu narysowanie maski wokół krawędzi przeszkody. Druga metoda polega na narysowaniu maski wokół obiektu w trybie wykluczania. Naciśnij klawisz W lub kliknij ikonę, aby przejść do trybu wykluczania i narysuj wielokąt wokół obiektu. Należy pamiętać, że podczas korzystania z trybu wykluczania należy również narysować maskę inkluzyjną wokół twarzy. Nie oznaczaj twarzy tylko maską wykluczającą. Naciśnij klawisz Q lub użyj ikony, aby przełączyć się z powrotem do trybu dołączania. Jeśli to możliwe, należy również oznaczyć przeszkodę na różnych ramkach.
Pamiętaj, że wszelkie zmiany kształtu maski mogą mieć wpływ na trening i łączenie twarzy deepfake. Być może będziesz musiał podjąć dodatkowe kroki podczas treningu, aby upewnić się, że wykluczona przeszkoda nie zmieni twarzy. Aby uzyskać najlepszy wynik, należy poradzić sobie z tymi przeszkodami za pomocą oprogramowania do przetwarzania końcowego.
Pobieranie i usuwanie
Po oznaczeniu twarzy możesz utworzyć kopię zapasową oznaczonych plików graficznych.
Uruchom: 5.XSeg) data_dst mask_fetch.bat
- Usunąć oryginalne pliki? ( t / n ) : Wybierz usunięcie plików oznaczonych Xseg z zestawu twarzy po pobraniu.
Spowoduje to skopiowanie wszystkich docelowych plików oznaczonych XSeg do data_dst/aligned_xseg i zostaniesz zapytany, czy chcesz usunąć oryginalne pliki.
Uruchom: 5.XSeg) data_src mask_fetch.bat
- Usunąć oryginalne pliki? ( t / n ) : Wybierz usunięcie plików oznaczonych Xseg z zestawu twarzy po pobraniu.
Spowoduje to skopiowanie wszystkich źródłowych plików oznaczonych XSeg do data_src/aligned_xseg i zostaniesz zapytany, czy chcesz usunąć oryginalne pliki.
Opcjonalnie: 5.XSeg) data_dst mask remove.bat
- [Konsola: !!! UWAGA: OZNACZONE WIELOKĄTY XSEG ZOSTANĄ USUNIĘTE Z RAMEK !!!]
Całkowicie usuń wszystkie utworzone docelowe etykiety XSeg. Używaj ostrożnie.
Opcjonalnie: 5.XSeg) data_src mask remove.bat
- [Konsola: !!! UWAGA: OZNACZONE WIELOKĄTY XSEG ZOSTANĄ USUNIĘTE Z RAMEK !!!]
Całkowicie usuń wszystkie utworzone źródłowe etykiety XSeg. Używaj ostrożnie.
Sztuczna inteligencja zamiana twarzy – Szkolenie z modeli XSeg
Następnym krokiem jest nauczenie modelu XSeg, aby mógł utworzyć maskę na podstawie dostarczonych etykiet.
Uruchom: 5.XSeg) pociąg.bat
- Które indeksy GPU wybrać?: Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić wyodrębnianie.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU. - Typ twarzy (h / mf / f / wf / head ): Wybierz typ twarzy do treningu XSeg.
[Etykietka: Połowa / środek twarzy / cała twarz / cała twarz / głowa. Wybierz taki sam, jak model deepfake.] - Batch_size ( 2 – 16 ): Wybierz rozmiar partii do szkolenia XSeg.
[Podpowiedź: Większy rozmiar partii jest lepszy do uogólnienia NN, ale może powodować błąd braku pamięci. Dostosuj tę wartość ręcznie do swojej karty graficznej.] - Włącz tryb wstępnego szkolenia ( y / n ): wybierz użycie zestawu twarzy _internal/pretrain_faces do szkolenia XSeg.
- [Konsola: Próba wykonania pierwszej iteracji. Jeśli wystąpi błąd, zmniejsz parametry modelu.]
- [Konsola: użytkownicy systemu Windows 10 WAŻNA uwaga. Należy ustawić to ustawienie, aby działać poprawnie. https://i.imgur.com/B7cmDCB.jpg ]
- [Uwaga: Deweloper zaleca użytkownikom systemu Windows 10 włączenie akceleracji sprzętowej planowania GPU w obszarze System > Wyświetlacz > Ustawienia grafiki. Przetestuj wydajność włączania/wyłączania w swoim systemie.]
Sztuczna inteligencja zamiana twarzy – Sztuczna inteligencja do manipulacji twarzą
Ustaw typ twarzy tak, aby był taki sam, jak twój zestaw twarzy. Prawdopodobnie możesz użyć największego rozmiaru wsadu, jednak jeśli szkolenie się nie powiedzie, możesz zmniejszyć rozmiar wsadu.
Okno poleceń pokaże bieżący czas, liczbę bieżących iteracji (cykli), czas przetwarzania bieżącej iteracji oraz wartość utraty (postęp szkolenia). Okno podglądu pokaże trenowane obrazy i maski oraz wykres wartości utraty w czasie. Użyj spacji, aby przełączać się między różnymi podglądami, a klawisza „P”, aby wygenerować bieżący podgląd. Możesz zobaczyć przekształcenia stosowane do obrazów, gdy trener próbuje dopasować etykiety do zestawu twarzy. Na początku maski będą zniekształcone i nierówne. Po pewnym czasie zauważysz, że maska nabiera spójnego kształtu z wyraźnymi krawędziami. Naciśnij przycisk „S”, aby zapisać trening, lub przycisk „Enter”, aby zapisać i wyjść.

Przykład: DeepFaceLab 2.0 XSeg Trainer Preview
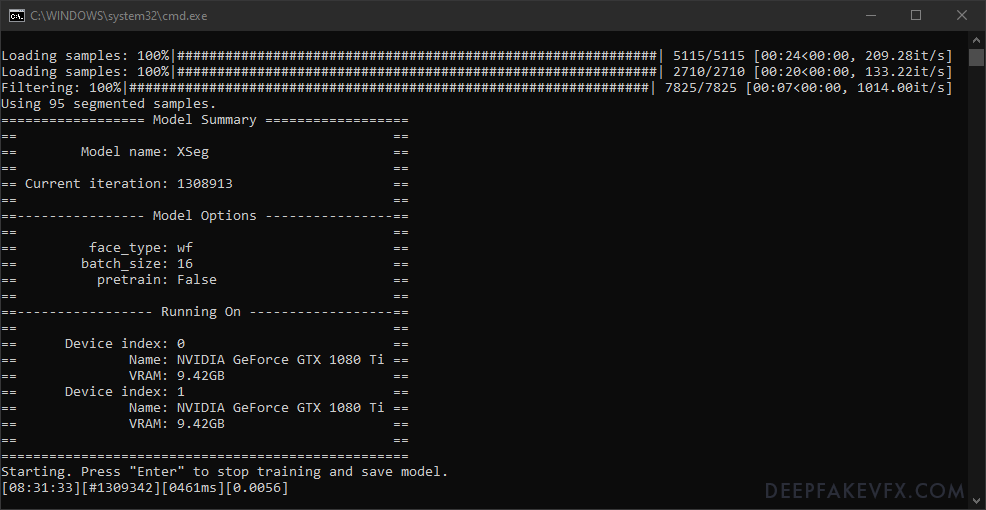
Przykład: Okno poleceń DeepFaceLab 2.0 XSeg Trainer
Kolejny bieg
Sztuczna inteligencja zamiana twarzy
Jeśli ponownie uruchomisz trenera XSeg, zobaczysz następujące opcje:
- Które indeksy GPU wybrać?: Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić wyodrębnianie.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU. - [Konsola: naciśnij enter w ciągu 2 sekund, aby zastąpić ustawienia modelu.]
Jeśli naciśniesz klawisz Enter, będziesz mógł zmienić te opcje:
- Zrestartować trening? ( t / n ): Wybierz, aby ponownie uruchomić trening XSeg.
[Podpowiedź: zresetuj wagę modelu i rozpocznij trening od zera.] - Batch_size ( 2 – 16 ): Wybierz rozmiar partii do szkolenia XSeg.
[Podpowiedź: Większy rozmiar partii jest lepszy do uogólnienia NN, ale może powodować błąd braku pamięci. Dostosuj tę wartość ręcznie do swojej karty graficznej.] - Włącz tryb wstępnego szkolenia ( y / n ): wybierz użycie zestawu twarzy _internal/pretrain_faces do szkolenia XSeg.
Nie można zmienić typu twarzy modelu.
Nakładanie maski XSeg
Maska XSeg została przeszkolona, ale aby jej użyć, należy najpierw zastosować ją do obrazów Faceset. Jeśli masz więcej niż jeden GPU, możesz ich użyć do jednoczesnego zastosowania maski źródłowej i docelowej.
Uruchom: 5.XSeg) data_dst przeszkolona maska Apply.bat
- Który indeks GPU wybrać?: Wybierz pojedynczy indeks GPU z listy, aby zastosować maskę XSeg.
Zastosuj przeszkoloną maskę XSeg do docelowego zestawu twarzy. Wymaga przeszkolonego modelu XSeg. Umieść przeszkolone pliki modelu XSeg w obszarze roboczym/modelu.
Uruchom: 5.XSeg) data_src przeszkolona maska Apply.bat
- Który indeks GPU wybrać?: Wybierz pojedynczy indeks GPU z listy, aby zastosować maskę XSeg.
Zastosuj przeszkoloną maskę XSeg do źródłowego zestawu twarzy. Wymaga przeszkolonego modelu XSeg. Umieść przeszkolone pliki modelu XSeg w obszarze roboczym/modelu.
Po zastosowaniu masek XSeg można rozpocząć lub kontynuować trenowanie modelu deepfake. Sugeruję jednak najpierw sprawdzić nałożoną maskę. Otwórz edytor XSeg, a następnie naciśnij klawisz odwrotu lub tyldy (`), aby przełączyć zastosowaną maskę. Użyj klawiszy „A” i „D”, aby przewijać obrazy i tworzyć nowe etykiety twarzy w razie potrzeby. Uruchom ponownie XSeg trainer, nałóż maskę i powtarzaj proces, aż nałożona maska będzie stosunkowo czysta.

Próbka: maska aplikacyjna DeepFaceLab 2.0 XSeg
Możesz także usunąć zastosowaną maskę XSeg i powrócić do domyślnej wygenerowanej maski bez wpływu na utworzone etykiety.
Opcjonalnie: 5.XSeg) data_dst przeszkolona maska remove.bat
- [Konsola: !!! UWAGA: NAŁOŻONE MASKI XSEG ZOSTANĄ USUNIĘTE Z RAMEK !!!]
Usuń przeszkoloną maskę XSeg z docelowego zestawu twarzy. Faceset zachowa domyślną wygenerowaną maskę. Nie ma to wpływu na etykiety XSeg.
Opcjonalnie: 5.XSeg) data_src przeszkolona maska remove.bat
- [Konsola: !!! UWAGA: NAŁOŻONE MASKI XSEG ZOSTANĄ USUNIĘTE Z RAMEK !!!]
Usuń przeszkoloną maskę XSeg ze źródłowego zestawu twarzy. Faceset zachowa domyślną wygenerowaną maskę. Nie ma to wpływu na etykiety XSeg.
Trening i łączenie z maskami XSeg
Kiedy trenujesz modelkę deepfake z maską XSeg, zauważysz, że obszar treningu twarzy dopasowuje się do nowego kształtu maski. Jeśli kontynuujesz trening z poprzednią maską, przystosowanie się modelu zajmie trochę czasu. W oknie podglądu treningu zobaczysz podglądy obu zastosowanych masek XSeg oraz maski przewidywanej. Przewidywana maska jest oparta na masce źródłowej i będzie używana do trenowania rzeczywistej (przewidywanej) twarzy deepfake. Ta przewidywana maska z czasem dostosuje się również do masek XSeg.
Po zakończeniu treningu możesz również użyć masek XSeg w procesie łączenia. Korzystanie z trybów maski XSeg podczas scalania wymaga przeszkolonego modelu XSeg w folderze /model. Należy trenować model, aż krawędzie maski będą dobrze zdefiniowane i spójne w zestawach twarzy.
Krok 6: Trening modelu Deepfake
Nadszedł czas, aby rozpocząć trenowanie modelu deepfake. Jest to oczywiście najważniejsza część procesu deepfake i przed rozpoczęciem będziesz musiał podjąć kilka krytycznych decyzji. Głównymi czynnikami, które zadecydują o ustawieniach Twojego modelu, są: dostępny sprzęt, pożądana jakość i realizm oraz ilość czasu, jaką możesz poświęcić na szkolenie. Być może będziesz musiał wypróbować wiele różnych ustawień, zanim stworzysz model, który może działać w twoim systemie z rozsądną szybkością.
Niektórych ustawień nie można zmienić po rozpoczęciu treningu. Musisz wcześniej wybrać typ modelu i trenera, architekturę modelu i warianty oraz wymiar kodera/dekodera. Niektóre opcje mogą i powinny być zmieniane w trakcie całego procesu, ponieważ istnieje kilka faz i kroków szkoleniowych. Ponadto niektóre procesy DeepFaceLab mogą zastąpić niektóre opcje, na przykład podczas wstępnego uczenia modelu.
Zapoznaj się z tabelą ustawień treningu modelu DeepFaceLab 2.0, aby uzyskać sugestie od innych użytkowników.
Modele i trenerzy
Do wyboru są 3 różne modele/trenażery: Quick96, SAEHD i AMP.
| Szybki96 | Predefiniowany model; przydatne do testowania. DF-UD, pełna twarz, rozdzielczość: 96, wielkość partii: 4 |
| SAEHD | Rzadki automatyczny koder HD. Standardowy model i trener większości deepfake’ów. |
| AMP | Wzmacniacz. Wyrazy twarzy miejsca docelowego są wzmacniane do źródła. |
Trenerzy modeli DeepFaceLab 2.0
Architektury i warianty – Sztuczna inteligencja zamiana twarzy
Do wyboru są 2 architektury i 4 warianty. Dzięki SAEHD możesz wybrać dowolną architekturę i dowolną kombinację 0-4 wariantów. Quick96 jawnie używa architektury DF-UD. AMP wyraźnie używa własnej architektury. Każdy typ modelu, architektura i opcja będą miały unikalny wpływ na wydajność systemu, wpływając na szybkość uczenia i jakość wyników.
| Architektura | Opis |
|---|---|
| DF | Ścisła interpretacja twarzy bez morfingu. Najbardziej dokładne i zgodne z danymi źródłowymi. Działa najlepiej, gdy źródło i miejsce docelowe mają podobne twarze i kolory. Umiejscowienie rysów twarzy (oczy, usta, nos itp.) Może się różnić w zależności od źródła i miejsca docelowego. Działa lepiej przy strzałach z przodu; możliwy gorszy wynik na profilach. Źródłowy zestaw twarzy musi mieć wystarczające pokrycie docelowego nachylenia, odchylenia i zakresów kolorów. |
| LIAH | Łagodna interpretacja twarzy z pewnymi morfingami. Bardziej dopasowuje się do twarzy docelowej. Dostosuje się do twarzy o odmiennym kształcie i kolorze. Rozmieszczenie rysów twarzy może być nieznacznie zmienione, aby pasowało do twarzy docelowej. Możliwy lepszy wynik na ekstremalnych kątach i brakujących danych. Większe odwzorowanie docelowego koloru i warunków oświetleniowych. |
Architektury modeli DeepFaceLab 2.0
| Wariant | Opis |
|---|---|
| W | Zwiększa podobieństwo do twarzy źródłowej. Wymaga więcej pamięci VRAM. |
| D | Popraw wydajność, skutecznie podwajając rozdzielczość przy tych samych kosztach obliczeniowych. Wymaga dłuższego szkolenia i zalecanego użycia wstępnie wytrenowanego modelu. Rozdzielczość należy zmienić o wielokrotność 32 (inne warianty: 16). |
| T | Zwiększa podobieństwo do twarzy źródłowej. |
| C | (Eksperymentalne) Ustawia funkcję aktywacji na jednostkę cosinus (domyślnie: Leaky ReLu). |
Warianty architektury modelu DeepFaceLab 2.0
Wejdziesz do architektury modelu, wpisując nazwę architektury, po której następuje myślnik i opcje wariantu (np. df, liae, df-ud, liae-udt,).
Autoenkoder i wymiary (wymiary)
Sztuczna inteligencja zamiana twarzy
Autoencoder to architektura sieci neuronowej zdolna do wykrywania struktury w [nieoznaczonych] danych w celu opracowania skompresowanej reprezentacji danych wejściowych. Autoenkodery to technika uczenia się bez nadzoru, w której wykorzystujemy sieci neuronowe do uczenia się reprezentacji.-Jeremy Jordan, Wprowadzenie do autoenkoderów
Autoenkoder, dekoder i wartość kodera kontrolują wymiary sieci neuronowej modelu, które bezpośrednio wpływają na zdolność modelu do uczenia się twarzy.
| Ciemny | Opis |
|---|---|
| Automatyczne przyciemnianie enkodera | Wymiary enkodera automatycznego. Wpływa na ogólną zdolność modelu do uczenia się twarzy. |
| Ściemniacze wewnętrzne | Międzywymiarowe (AMP). Wpływa na ogólną zdolność modelu do uczenia się twarzy. Ustaw wartość równą lub wyższą niż przyciemnienia Auto Encoder. |
| Dim enkodera | Wymiary enkodera. Wpływa na zdolność kodera (danych wejściowych) do przetwarzania twarzy. |
| Diody dekodera | Wymiary dekodera. Wpływa na zdolność dekodera (wyjścia) do odtwarzania twarzy. |
| Przyciemnienie maski dekodera | Wymiary maski dekodera. Wpływa na jakość wyuczonych masek; może wpływać na trening. |
DeepFaceLab 2.0 Autoencoder / Encoder / Decoder Opisy wymiarów
Wymiary powinny zostać zmienione we wszystkich koderach i dekoderach, co oznacza, że jeśli zwiększysz lub obniżysz AE Dim, powinieneś również zwiększyć lub obniżyć Dim E i D. Przyciemnienia maski dekodera określają jakość wyuczonych masek i można je zmieniać niezależnie, jeśli wolisz. Inter Dimy są używane tylko w modelu AMP. Ogólnie rzecz biorąc, modele o wyższej rozdzielczości wymagają większych wymiarów.
Rozmiar partii
Rozmiar wsadu jest jedną z najważniejszych opcji w DeepFaceLab, ponieważ określa liczbę obrazów, które można przetworzyć w jednym czasie (na iterację). Większy rozmiar partii doprowadzi do lepszego uogólnienia modelu i szybszego uczenia (mniej iteracji). Bardzo mały rozmiar partii (<=4) będzie znacznie wolniejszy, a model może mieć problemy z uogólnieniem rysów twarzy, koloru itp. Bardzo duży rozmiar partii może ostatecznie skutkować zmniejszonym zwrotem z wydajności, a wśród twórców toczy się debata na temat „optymalnej wielkości partii”. Zaleca się osiągnięcie wielkości partii co najmniej 4, a najlepiej w zakresie 8-16.
Ponadto Rozmiar wsadu można zmienić w dowolnym momencie, a dostępne są różne opcje modeli, które zużywają mniej lub więcej zasobów systemowych, zmuszając użytkownika do zmiany rozmiaru wsadu. Ponadto, jeśli zdecydujesz się użyć wstępnie przeszkolonego modelu, może być konieczna zmiana rozmiaru partii, aby działała na twoim sprzęcie. Możesz pobrać wstępnie przeszkolony model, który został wyprodukowany na znacznie wydajniejszym systemie, zmniejszyć rozmiar wsadu i trenować z własnymi obrazami.
Ustawienia treningu modelu
Sztuczna inteligencja zamiana twarzy
Zapoznaj się z tabelą ustawień treningu modelu DeepFaceLab 2.0, aby uzyskać sugestie od innych użytkowników.
Wszystkie ustawienia i opcje szkolenia modeli (SAEHD)
| Ustawienie treningu | Opis |
|---|---|
| Automatyczna kopia zapasowa co N godzin ( 0 – 24 ) | Ustaw interwał automatycznej kopii zapasowej. [Podpowiedź: Automatyczna kopia zapasowa plików modelu z podglądem co N godzin. Ostatnia kopia zapasowa znajduje się w modelu/<>_autobackups/01] |
| Zapisz historię podglądu ( t / n ) | Wybierz, aby zapisać historię obrazu podglądu (co 30 iteracji). [Podpowiedź: historia podglądu zostanie zapisana w folderze _history.] |
| Wybierz obraz do historii podglądu ( t / n ) | (Warunkowo: Zapisz historię podglądu) Po rozpoczęciu szkolenia zostaniesz poproszony o wybranie obrazu podglądu do generowania historii. |
| Docelowa iteracja | Ustaw iterację docelową na zakończenie i zapisz szkolenie. Ustaw na 0, aby trenować nieprzerwanie. |
| Odwróć losowo twarze SRC ( t / n ) | [Etykietka: Losowe odwrócenie w poziomie zestawu SRC. Obejmuje więcej kątów, ale twarz może wyglądać mniej naturalnie.] |
| Odwróć losowo twarze DST ( t / n ) | [Etykietka: Losowe odwrócenie w poziomie widoku DST. Sprawia, że generalizacja src->dst jest lepsza, jeśli src losowe przerzucanie nie jest włączone.] |
| Wielkość partii | [Podpowiedź: Większy rozmiar partii jest lepszy do uogólnienia NN, ale może powodować błąd braku pamięci. Dostosuj tę wartość ręcznie do swojej karty graficznej.] |
Sztuczna inteligencja zamiana twarzy
| Ustawienie treningu | Opis |
| Rozdzielczość ( 64 – 640 ) | [Podpowiedź: Większa rozdzielczość wymaga więcej pamięci VRAM i czasu na trenowanie. Wartość zostanie dostosowana do wielokrotności 16 i 32 dla -d archi.] |
| Typ twarzy (h/mf/f/wf/głowa) | [Podpowiedź: połowa / środek twarzy / cała twarz / cała twarz / głowa. Pół twarzy ma lepszą rozdzielczość, ale zakrywa mniejszą powierzchnię policzków. Środkowa część twarzy jest o 30% szersza niż połowa twarzy. „Cała twarz” obejmuje całą powierzchnię twarzy, w tym czoło. „head” obejmuje całą głowę, ale wymaga XSeg dla src i dst faceset.] |
| Architektura AE | [Etykietka: „df” pozwala lepiej zachować tożsamość twarzy. „liae” może naprawić zbyt różne kształty twarzy. „-u” zwiększyło podobieństwo twarzy. „-d” (eksperymentalne) podwojenie rozdzielczości przy takim samym koszcie obliczeniowym. Przykłady: df, liae, df-d, df-ud, liae-ud, …] |
| Wymiary AutoEncodera ( 32 – 1024 ) | [Etykietka: Wszystkie informacje o twarzy zostaną spakowane do przyciemnienia AE. Jeśli ilość przyciemnień AE nie wystarczy, to na przykład zamknięte oczy nie zostaną rozpoznane. Więcej dimów jest lepszych, ale wymaga więcej VRAM. Możesz precyzyjnie dopasować rozmiar modelu do swojego GPU.] |
| Wymiary enkodera ( 16 – 256 ) | [Podpowiedź: Więcej przyciemnień pomaga rozpoznać więcej rysów twarzy i uzyskać ostrzejszy efekt, ale wymaga więcej pamięci VRAM. Możesz precyzyjnie dopasować rozmiar modelu do swojego GPU.] |
| Wymiary dekodera ( 16 – 256 ) | Podpowiedź: Więcej przyciemnień pomaga rozpoznać więcej rysów twarzy i uzyskać ostrzejszy efekt, ale wymaga więcej pamięci VRAM. Możesz precyzyjnie dopasować rozmiar modelu do swojego GPU.] |
| Wymiary maski dekodera ( 16 – 256 ) | [Podpowiedź: Typowe wymiary maski = wymiary dekodera / 3. Jeśli ręcznie wycinasz przeszkody z maski dst, możesz zwiększyć ten parametr, aby uzyskać lepszą jakość.] |
Sztuczna inteligencja zamiana twarzy
Ustawienie treningu | Opis |
| Trening w maskach ( t / n ) | (Warunkowo: Typ twarzy wf lub głowa) [Podpowiedź: Ta opcja jest dostępna tylko dla typu „cała_twarz” lub „głowa”. Trening z maską przycina obszar treningowy do maski full_face lub maski XSeg, dzięki czemu sieć będzie prawidłowo trenować twarze.] |
| Priorytet oczu i ust ( t / n ) | [Podpowiedź: pomaga rozwiązać problemy z oczami podczas treningu, takie jak „obce oczy” i niewłaściwy kierunek oczu. Zwiększa również szczegółowość zębów.] |
| Jednolity rozkład odchylenia próbek ( t / n ) | [Podpowiedź: pomaga naprawić rozmyte ściany boczne ze względu na niewielką ich liczbę w zestawie twarzy.] |
| Maska rozmycia ( t / n ) | [Podpowiedź: Zamazuje pobliski obszar poza nałożoną maską na twarz próbek treningowych. W rezultacie tło w pobliżu twarzy jest wygładzone i mniej widoczne na zamienionej twarzy. Wymagana jest dokładna maska xseg w zestawach twarzy src i dst.] |
| Umieść modele i optymalizator na GPU ( t / n ) | [Podpowiedź: Gdy trenujesz na jednym GPU, domyślnie wagi modelu i optymalizatora są umieszczane na GPU, aby przyspieszyć proces. Możesz umieścić je na procesorze, aby zwolnić dodatkową pamięć VRAM, a tym samym ustawić większe wymiary.] |
| Używasz optymalizatora AdaBelief? ( tak / nie ) | [Podpowiedź: użyj optymalizatora AdaBelief. Wymaga więcej VRAM, ale dokładność i uogólnienie modelu jest wyższa.] |
| Wykorzystaj spadek współczynnika uczenia się ( n / y / procesor ) | [Podpowiedź: Gdy twarz jest wystarczająco wytrenowana, możesz włączyć tę opcję, aby uzyskać dodatkową ostrość i zredukować drgania subpikseli przy mniejszej liczbie iteracji. Włączono go przed wyłączeniem losowego wypaczania i przed GAN. n – wyłączone. y – włączony procesor – włączony na procesorze. Pozwala to nie używać dodatkowej pamięci VRAM, poświęcając 20% czasu iteracji.] |
Sztuczna inteligencja zamiana twarzy
Ustawienie treningu | Opis |
| Włącz losowe wypaczanie próbek ( t / n ) | [Podpowiedź: losowe wypaczenie jest wymagane, aby uogólnić mimikę obu twarzy. Kiedy twarz jest wystarczająco wyszkolona, możesz ją wyłączyć, aby uzyskać dodatkową ostrość i zmniejszyć drgania subpikseli przy mniejszej liczbie iteracji.] |
| Losowy odcień/nasycenie/intensywność światła (0,0 – 0,3) | [Podpowiedź: Losowy odcień/nasycenie/intensywność światła zastosowany do zestawu twarzy src tylko na wejściu sieci neuronowej. Stabilizuje zakłócenia kolorów podczas zamiany twarzy. Zmniejsza jakość transferu kolorów, wybierając najbliższy w src faceset. Zatem zestaw twarzy src musi być wystarczająco zróżnicowany. Typowa dokładna wartość to 0,05] |
| Moc GAN ( 0,0 – 5,0 ) | [Podpowiedź: Wymusza na sieci neuronowej zapamiętywanie drobnych szczegółów twarzy. Włącz go tylko wtedy, gdy twarz jest wystarczająco wyszkolona za pomocą lr_dropout(on) i random_warp(off) i nie wyłączaj. Im wyższa wartość, tym większe prawdopodobieństwo wystąpienia artefaktów. Typowa dokładna wartość to 0,1] |
| Rozmiar poprawki GAN (3 – 640) | (Warunkowo: moc GAN) [Podpowiedź: Im większy rozmiar poprawki, tym wyższa jakość, tym więcej wymaganej pamięci VRAM. Ostre krawędzie można uzyskać nawet przy najniższym ustawieniu. Typowa dokładna wartość to rozdzielczość / 8.] |
| Wymiary GAN ( 4 – 512 ) | (Warunkowo: moc GAN) [Podpowiedź: wymiary sieci GAN. Im większe wymiary, tym więcej wymaganej pamięci VRAM. Ostre krawędzie można uzyskać nawet przy najniższym ustawieniu. Typowa wartość grzywny to 16.] |
Sztuczna inteligencja zamiana twarzy
| Ustawienie treningu | Opis |
| Siła „prawdziwej twarzy”. ( 0,0000 – 1,0 ) | (Warunkowo: architektura DF) [Etykietka: opcja eksperymentalna. Rozróżnia wynikową twarz, aby była bardziej podobna do src face. Wyższa wartość – silniejsza dyskryminacja. Typowa wartość to 0,01. Porównanie – https://i.imgur.com/czScS9q.png] |
| Moc stylu twarzy ( 0,0 – 100,0 ) | [Podpowiedź: Dowiedz się, czy kolor przewidywanej twarzy jest taki sam jak dst wewnątrz maski. Jeśli chcesz użyć tej opcji z „whole_face”, musisz użyć przeszkolonej maski XSeg. Ostrzeżenie: włącz ją dopiero po 10 tys. iteracji, gdy przewidywana twarz jest wystarczająco wyraźna, aby rozpocząć naukę stylu. Zacznij od wartości 0,001 i sprawdź historię zmian. Włączenie tej opcji zwiększa szansę na zawalenie się modelu.] |
| Moc stylu tła ( 0.0 – 100.0 ) | [Podpowiedź: Dowiedz się, czy obszar na zewnątrz maski przewidywanej twarzy jest taki sam jak czas letni. Jeśli chcesz użyć tej opcji z „whole_face”, musisz użyć przeszkolonej maski XSeg. W przypadku całej twarzy musisz użyć przeszkolonej maski XSeg. Może to sprawić, że twarz będzie bardziej przypominać dst. Włączenie tej opcji zwiększa prawdopodobieństwo upadku modelu. Typowa wartość to 2,0] |
| Transfer kolorów dla src faceset ( none / rct / lct / mkl / idt / sot ) | [Podpowiedź: Zmień rozkład kolorów próbek src zbliżony do próbek dst. Wypróbuj wszystkie tryby, aby znaleźć najlepszy.] |
| Włącz przycinanie gradientu ( t / n ) | [Podpowiedź: Przycinanie gradientu zmniejsza ryzyko zawalenia się modelu, poświęcając szybkość uczenia.] |
| Włącz tryb przedtreningowy ( t / n ) | [Podpowiedź: Wstępnie wytrenuj model z dużą liczbą różnych twarzy. Następnie model może być użyty do szybszego trenowania podróbek. Wymusza random_warp=N, random_flips=Y, gan_power=0.0, lr_dropout=N, styles=0.0, uniform_yaw=Y] |
Ustawienia treningu modelu DeepFaceLab 2.0 (SAEHD)
Wstępne uczenie i używanie wstępnie wytrenowanych modeli
Sztuczna inteligencja zamiana twarzy
Możesz wstępnie wytrenować model, aby uczyć się rysów twarzy i kolorów z różnych twarzy. Ten wstępnie wytrenowany model może być następnie użyty do uruchomienia dowolnego deepfake z tymi samymi ustawieniami modelu podstawowego. DeepFaceLab obejmuje wstępnie wytrenowany zestaw twarzy Flickr Faces HQ (FFHQ) z ogólną wstępnie wytrenowaną maską całej twarzy, która została już zastosowana do wyrównanych obrazów. Starsze wersje DFL korzystają z zestawu danych CelebA. Bieżące obrazy można znaleźć w folderze oznaczonym jako _internal/pretrain_faces jako plik faceset.pak. Wyświetl zestaw twarzy, kopiując plik do data_src/aligned i uruchamiając plik 4.2) data_src util faceset unpack.bat. Tym samym Możesz utworzyć własny zestaw twarzy do uczenia wstępnego z obrazów w folderze data_src/aligned, uruchamiając plik 4.2) data_src util faceset pack.bat i przenosząc wynikowy plik faceset.pak do folderu _internal/pretrain_faces.

DeepFaceLab 2.0 Wstępny zestaw twarzy (FFHQ)
Po pobraniu lub zaimportowaniu wstępnie wytrenowanego modelu do folderu obszaru roboczego/modelu nie będzie można zmienić podstawowych ustawień modelu, takich jak typ powierzchni, architektura i wymiary. Jeśli model nie działa w twoim systemie, powinieneś zmniejszyć rozmiar wsadu i rozważyć zwiększenie rozmiaru pliku stronicowania. Jeśli model ładuje się pomyślnie, możesz rozważyć zwiększenie rozmiaru partii. W tym momencie możesz kontynuować trening wstępny lub wyłączyć tryb treningu wstępnego, aby rozpocząć normalny trening na zestawach twarzy.
Pobierz wstępnie wytrenowane modele DeepFaceLab, aby przyspieszyć szkolenie w zakresie deepfake.
DeepFaceLab zastąpi niektóre ustawienia modelu po włączeniu wstępnego uczenia.
| Nazwa ustawienia | Zastąp wartość |
|---|---|
| Porzucenie wskaźnika uczenia się | FAŁSZ |
| Losowe wypaczenie | FAŁSZ |
| JEDNAKŻE | 0.0 |
| Losowa moc HSV | 0.0 |
| Moc stylu twarzy | 0.0 |
| Moc stylu tła | 0.0 |
| Jednolite odchylenie | PRAWDA |
| Losowo odwracaj twarze SRC | PRAWDA |
| Losowo odwracaj twarze DST | PRAWDA |
DeepFaceLab 2.0 Wstępne wartości nadpisań
Szkolenie modelu Deepfake
Uruchom: 6) pociąg (AMP/Quick96/SAEHD)
Oprogramowanie załaduje wszystkie zestawy twarzy i spróbuje uruchomić pierwszą iterację szkolenia. Jeśli się powiedzie, otworzy się okno podglądu treningu. Jeśli trenażer nie działa, należy dostosować ustawienia modelu lub zoptymalizować system .
W oknie poleceń zostanie wyświetlona lista bieżących ustawień modelu i sprzętu. Poniżej znajduje się aktualny czas, liczba bieżących iteracji (cykli), czas przetwarzania bieżącej iteracji, źródłowa wartość strat i docelowa wartość strat. Te wartości strat reprezentują dokładność treningu i z czasem będą zbliżać się do zera, więc im niższa wartość, tym lepsze będą wyniki. Liczby te będą stale aktualizowane w miarę postępu szkolenia. Jeśli liczby przestaną się aktualizować, oznacza to, że trener zawiesił się i prawdopodobnie ulegnie awarii.
Sztuczna inteligencja zamiana twarzy
Poświęć chwilę, aby spojrzeć na okno podglądu. U góry znajdują się niektóre polecenia klawiaturowe. Poniżej wykres wartości strat w czasie oraz podgląd obrazów treningowych.
Naciśnij klawisz P, aby zaktualizować okno podglądu i zwróć uwagę na zmianę wykresu i obrazów. Linie te przedstawiają wartości strat (dokładność), więc im niższa linia, tym lepszy wynik. Podgląd obrazu ma kilka kolumn pokazujących przetwarzane obrazy źródłowe i docelowe oraz maski, a także przewidywaną twarz deepfake. Za pomocą tego okna podglądu zdecydujesz, kiedy chcesz zakończyć trening. Naciśnij Enter, aby zapisać model i wyjść.
Przebieg pracy przy szkoleniu modeli (SAEHD)
- Faza 1: Trening wstępny (opcjonalnie)
- Krok 1 — Wstępnie wytrenuj model lub zaimportuj wstępnie wytrenowany model.
- Wprowadź wszystkie ustawienia modelu.
- Włącz tryb Pretrain.
- Krok 1 — Wstępnie wytrenuj model lub zaimportuj wstępnie wytrenowany model.
- Faza 2: Uogólnienie / Wypaczone szkolenie
- Krok 2 – Losowe wypaczenie
- Włącz Random Warp próbek
- Włącz trening z maską (tylko WF/głowa)
- Wyłącz True Face Power (tylko modele DF)
- Wyłącz GANA
- Wyłącz tryb Pretrain.
- (Opcjonalnie) Odwróć SRC losowo, Odwróć losowo DST, Tryb transferu kolorów, Losowy HSL
- (Opcjonalnie) Dodaj lub usuń obrazy zestawu twarzy i zmień maski podczas fazy warp
- (Opcjonalnie) W razie potrzeby włącz przycinanie gradientu
- Krok 3 – Priorytet oczu i ust (opcjonalnie)
- Włącz priorytet oczu i ust
- Krok 4 — Jednolite odchylenie (opcjonalnie)
- Wyłącz priorytet oczu i ust
- Włącz Jednolity rozkład odchylenia próbek
- Krok 5 – Rezygnacja ze wskaźnika uczenia się (opcjonalnie)
- Włącz opcję Użyj porzucenia wskaźnika uczenia się
- (Opcjonalnie) Wyłącz opcję Jednolity rozkład odchylenia próbek
- Krok 2 – Losowe wypaczenie
- Faza 3: Normalizacja / Regularny trening
- Krok 6 – Regularny trening
- Wyłącz losowe wypaczenie
- Wyłącz jednolite odchylenie
- Wyłącz priorytet oczu i ust
- Wyłącz Użyj rezygnacji z szybkości uczenia się
- Krok 7 – Styl i kolor (opcjonalnie)
- Włącz maskę rozmycia, moc „True Face” (tylko DF), moc stylu twarzy, moc stylu tła
- Krok 8 – Priorytet oczu i ust (opcjonalnie)
- Włącz priorytet oczu i ust
- Krok 9: Jednolite odchylenie (opcjonalnie)
- Wyłącz priorytet oczu i ust
- Włącz Jednolity rozkład odchylenia próbek
- Krok 10 — LRD (opcjonalnie)
- Włącz opcję Użyj porzucenia wskaźnika uczenia się
- Wyłącz priorytet oczu i ust
- (Opcjonalnie) Wyłącz opcję Jednolity rozkład odchylenia próbek
- Krok 6 – Regularny trening
- Faza 4: doskonalenie / szkolenie GAN (opcjonalnie)
- Krok 11 – GAN
- Wyłącz priorytet oczu i ust
- Wyłącz Jednolity rozkład odchylenia próbek
- Ustaw moc GAN
- Ustaw rozmiar poprawki GAN
- Ustaw wymiary GAN
- Krok 11 – GAN
Krok 6.1: Eksportuj jako DFM dla DeepFaceLive – OPCJA
Eksportuj model deepfake w formacie .dfm do pracy w DeepFaceLive . Instrukcje znajdują się w często zadawanych pytaniach użytkowników DeepFaceLive .
Pomiń ten krok, jeśli nie używasz DeepFaceLive.
Uruchom: 6) wyeksportuj AMP jako dfm.bat lub 6) wyeksportuj SAEHD jako dfm.bat
Eksportuj model AMP lub SAEHD jako format .dfm do pracy w DeepFaceLive.
- Wybierz jeden z zapisanych modeli lub wprowadź nazwę, aby utworzyć nowy model.
[r]: zmień nazwę
[d]: usuń
[Uwaga: wybierz indeks modelu do wyeksportowania jako dfm.] - Eksportować skwantyzowane? ( y / n ): Kwantyzacja zmniejsza precyzję, ale skutkuje mniejszym rozmiarem modelu i szybszymi obliczeniami. Przeczytaj więcej o optymalizacji Tensorflow .
[Podpowiedź: Przyspiesza eksportowanie modelu. Jeśli masz problemy, wyłącz tę opcję.]
Sztuczna inteligencja zamiana twarzy
Krok 7: Połącz model Deepfake z obrazami ramek
Teraz, gdy szkolenie jest zakończone, możesz scalić twarze i utworzyć ostateczne obrazy klatek typu deepfake.
Uruchom: 7) połącz (AMP/Quick96/SAEHD)
- Wybierz jeden z zapisanych modeli lub wprowadź nazwę, aby utworzyć nowy model.
[ r ] : zmień nazwę
[ d ] : usuń
[Uwaga: Wybierz model według indeksu do scalenia.] - Wybierz jeden lub kilka identyfikatorów GPU (oddzielonych przecinkami).
Wybierz jeden lub więcej indeksów GPU z listy, aby uruchomić ekstrakcję.
Zaleca się używanie identycznych urządzeń przy wyborze wielu indeksów GPU.
Model zostanie zainicjowany, aw oknie poleceń zostanie wyświetlone podsumowanie bieżącego modelu.
- Użyj interaktywnej fuzji? ( t / n ): Wybierz, czy chcesz użyć interaktywnego (wizualnego podglądu) scalania.
Tryb nieinteraktywny nie ma okna podglądu. - Liczba pracowników? ( 1-16 ): Określ liczbę procesów.
[Podpowiedź: Określ liczbę wątków do przetworzenia. Niska wartość może wpłynąć na wydajność. Wysoka wartość może spowodować błąd pamięci. Wartość nie może być większa niż liczba rdzeni procesora.]
Zostaną zebrane wyrównania obrazu i obliczone zostaną wektory ruchu.
- Użyć zapisanej sesji? ( t / n ) : Jeśli korzystałeś już z fuzji, możesz wznowić z zapisanymi ustawieniami.
Interaktywna fuzja – Sztuczna inteligencja zamiana twarzy
Tryb interaktywny pokazuje mapę wejść z klawiatury, wizualny podgląd scalonego obrazu oraz wyświetla aktualny numer klatki i ustawienia. Będziesz mógł zmienić ustawienia na każdej pojedynczej ramce. Możesz zapisać sesję i wznowić ją później.
W trybie nieinteraktywnym zostaniesz poproszony o wprowadzenie wszystkich wartości w kolejności, następnie zostaniesz poproszony o podanie liczby pracowników. Wszystkie klatki zostaną przetworzone; nie można zmieniać ustawień dla poszczególnych klatek. Nie będziesz mógł zapisać ani załadować sesji.
W trybie interaktywnym otworzy się okno łączenia pokazujące mapę wejść z klawiatury, natomiast okno poleceń wyświetli aktualny numer klatki i ustawienia (config/cfg). Po wybraniu okna mapy klawiatury naciskaj klawisz Tab, aby przełączać się między mapą klawiatury a podglądem obrazu. Jeśli zobaczysz podgląd czarnego kwadratu lub pierwsza klatka nie ma twarzy, po prostu użyj klawiszy < i >, aby przewinąć do pierwszej klatki lub twarzy. Zauważysz bieżący numer klatki i ustawienia wyświetlane w oknie poleceń.
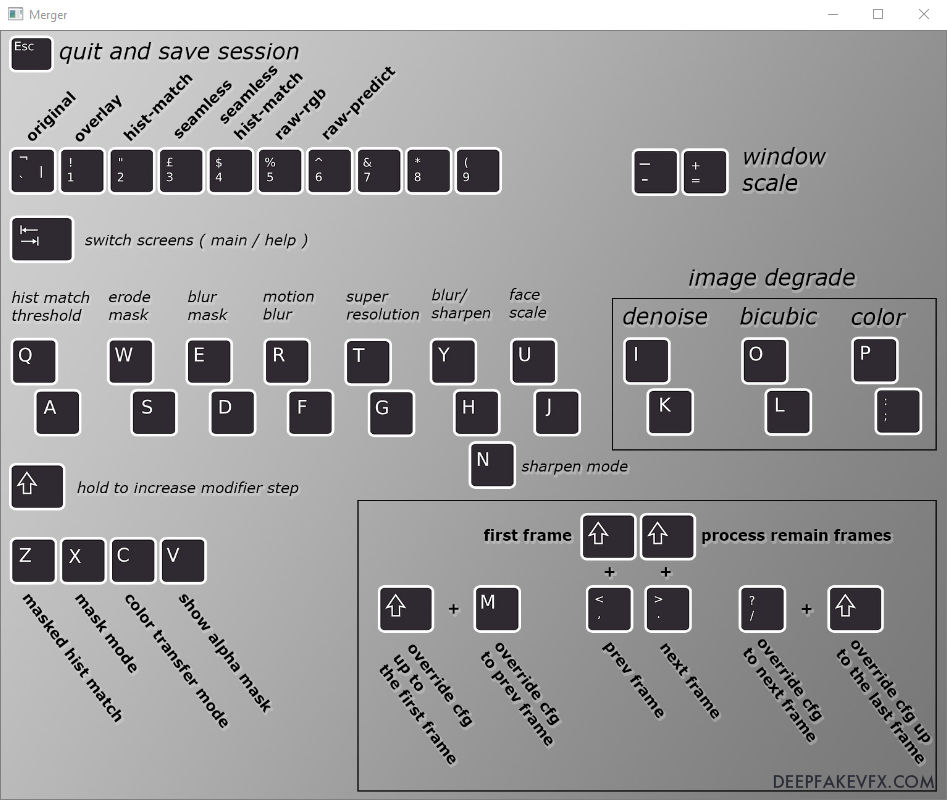
Sztuczna inteligencja zamiana twarzy
Schemat: wejścia klawiatury DeepFaceLab 2.0 Merger
Po zmianie trybów i modyfikatorów zobaczysz wartości wyświetlane w oknie poleceń.

Przykład: Okno poleceń połączenia DeepFaceLab 2.0 – Sztuczna inteligencja zamiana twarzy na wideo
Aby poruszać się po ramkach i zmieniać ustawienia, musisz mieć otwarte okno podglądu obrazu (Tab).

Przykład: Okno podglądu połączenia DeepFaceLab 2.0 – Sztuczna inteligencja zamiana twarzy na wideo
Polecenia nawigacji i przetwarzania ramek
Najprostsze połączenie obejmowałoby 3 kroki:
- Zmień tryby i modyfikatory w pierwszej klatce
- Zastąp ustawienia (config/cfg) do ostatniej klatki [Shift + /]
- Przetwarzaj pozostałe klatki [Shift + >]
Sztuczna inteligencja zamiana twarzy na wideo
Scalanie na poziomie pośrednim polegałoby na zmianie trybów i modyfikatorów, zastąpieniu ostatniej klatki, a następnie przejściu do następnego ujęcia lub sceny, zmianie i zastąpieniu konfiguracji oraz powtórzeniu procesu dla każdego innego ujęcia lub sceny w filmie.
Zaawansowane scalanie polegałoby na modyfikowaniu konfiguracji „w locie” poprzez zmianę ustawień, gdy aktor lub kamera się poruszają lub gdy zmienia się oświetlenie. Możesz także chcieć zmodyfikować konfigurację specjalnie dla ramek zawierających przeszkody. Należy pamiętać, że połączenie DeepFaceLab nie obsługuje klatek kluczowych, co oznacza, że nie ma animacji ani interpolacji między klatkami.
| Nawigacja / Proces | Wejście klawiatury |
|---|---|
| Wyjdź i zapisz sesję | wyjście |
| Przełącz ekrany (główny/pomoc) | Patka |
| Skala okna (w dół) | – |
| Skala okna (w górę) | + |
| Poprzednia ramka | < |
| Następna ramka | > |
| Pierwsza ramka | Przesunięcie + < |
| Przetwórz pozostałe ramki | Shift + > |
| Zastąp cfg poprzednią klatką | M |
| Zamień cfg do następnej klatki | / |
| Zamień cfg do pierwszej klatki | Shift + M |
| Zastąp cfg do ostatniej klatki | Shift + / |
| Pokaż maskę alfa | W |
Nawigacja scalająca DeepFaceLab 2.0 – Sztuczna inteligencja zamiana twarzy na wideo
Tryby nakładania – Sztuczna inteligencja zamiana twarzy
Tryb nakładania [`,1-6] określa, w jaki sposób przewidywana twarz zostanie nałożona (ułożona warstwowo) na obrazy docelowe.
| Tryb nakładki | Opis |
|---|---|
| [`] Oryginał | Brak nakładki. Wyświetla oryginalny obraz ramki docelowej. |
| [1] Nakładka | Prosta nakładka. |
| [2] Hist-Match | Nakładanie przy użyciu dopasowania histogramu. Włącza „próg dopasowania histologicznego” [Q/A]. Przełącz tryb zamaskowany/niezamaskowany [Z] |
| [3] Bez szwu | Używa OpenCV Poisson Seamless Cloning do mieszania twarzy |
| [4] Bezproblemowe dopasowanie hist | Połączenie Seamless i Hist-Match. Włącza „próg dopasowania histologicznego” [Q/A]. |
| [5] Surowy RGB | Nakłada cały wyuczony obszar twarzy (kwadrat) bez maski |
| [6] Przewidywane na surowo | Eksportuj tylko przewidywaną (wyuczoną) twarz. Kwadratowy obraz jak faceset. |
Tryby nakładki DeepFaceLab 2.0 – Sztuczna inteligencja zamiana twarzy na wideo
Tryby maski – Sztuczna inteligencja zamiana twarzy na wideo
Tryb maski (X) pozwala wybrać kształt maski do użycia. Możesz przełączać widok nakładki maski za pomocą Pokaż maskę alfa (V).
| Tryb maski [X] | Opis |
|---|---|
| czas letni | Domyślnie wygenerowana maska miejsca docelowego |
| wyuczony-prd | Maska nauczona podczas treningu na podstawie źródła |
| wyuczony-dst | Maska nauczona podczas treningu na podstawie miejsca docelowego |
| wyuczony-prd*uczony-dst | Połączone wyuczone maski przy użyciu najmniejszego obszaru |
| wyuczony-prd+uczony-dst | Połączone wyuczone maski wykorzystujące największy obszar |
| XSeg-prd | Maska XSeg oparta na źródle (wymaga modelu XSeg) |
| XSeg-dst | Maska XSeg na podstawie miejsca docelowego (wymaga modelu XSeg) |
| XSeg-prd*XSeg-dst | Kombinowane maski XSeg wykorzystujące najmniejszą powierzchnię (wymaga modelu XSeg) |
| wyuczony-prd * wyuczony-dst*XSeg-prd*XSeg-dst | Maski łączone wykorzystujące najmniejszą powierzchnię (wymaga modelu XSeg) |
| pełny | Maska rozciąga się do granicy twarzy (kwadrat). Podobnie jak bez maski. |
Tryby maski łączenia DeepFaceLab 2.0 – Sztuczna inteligencja zamiana twarzy na wideo
Tryby transferu kolorów
Sztuczna inteligencja zamiana twarzy na wideo
Tryby transferu koloru [C] przenoszą kolor z docelowej twarzy na przewidywaną twarz.
| Tryb transferu kolorów [C] | Opis |
|---|---|
| Nic | Brak transferu kolorów |
| rct | Reinhard Color Transfer (zamaskowany) |
| lct | Liniowy transfer kolorów (transformacja liniowa) |
| mkl | Liniowy Monge-Kantorowicz |
| mkl-m | MKL zamaskowany |
| idt | Iteracyjny transfer dystrybucji |
| idt-m | IDT zamaskowany |
| sot-m | Zamaskowany optymalny transport w plasterkach |
| mix-m | Mieszanka RCT/LCT/SOT zamaskowana (?) |
DeepFaceLab 2.0 Połącz tryby transferu kolorów – Sztuczna inteligencja zamiana twarzy na wideo
Wszystkie tryby scalania i modyfikatory – Sztuczna inteligencja zamiana twarzy
| Połącz tryby i filtry | Opis |
|---|---|
| Tryb [`,1-6]. | Tryb nakładania obrazu. |
| [Z] Zamaskowane dopasowanie hist | Zamaskowany lub niezamaskowany dopasowanie histogramu. |
| [Q, A] Próg jego dopasowania | Próg dopasowania histogramu. |
| [W,S] Erode Mask Modifier | Rozszerz lub zawęź obszar maski. |
| [E,D] Modyfikator maski rozmycia | Wtapiaj krawędź maski. |
| [R,F] Moc rozmycia ruchu | Moc rozmycia ruchu. W jednej ramce może znajdować się tylko jedna twarz. |
| [U,J] Wyjściowa skala twarzy | Skaluj rozmiar twarzy większy lub mniejszy. |
| [C] Tryb transferu kolorów | Przenieś kolor na twarz. |
| [N] Tryb wyostrzania | Wybierz tryb wyostrzania. |
| [Y,H] Stopień rozmycia/wyostrzenia | Rozmycie lub wyostrzenie twarzy. |
| [T,G] Moc superrozdzielczości | Ustaw moc superrozdzielczości |
| [I,K] Moc usuwania szumów obrazu | Ustaw moc usuwania szumów obrazu |
| [O,L] Dwusześcienna moc degradacji | Ustaw dwusześcienną moc degradacji. |
| [P,;] Moc degradacji koloru | Ustaw moc degradacji kolorów. |
Tryby i modyfikatory łączenia DeepFaceLab 2.0 -Sztuczna inteligencja zamiana twarzy na wideo
Sztuczna inteligencja zamiana twarzy – Połączenie nieinteraktywne
W trybie nieinteraktywnym zostaniesz poproszony o wprowadzenie wszystkich wartości w kolejności. Następnie zostaniesz poproszony o podanie liczby pracowników. Wszystkie klatki zostaną przetworzone; nie można zmieniać ustawień dla poszczególnych klatek. Nie będziesz mógł zapisać ani załadować sesji.
- Wybierz tryb:
- (0) oryginał
- (1) nakładka
- (2) dopasowanie hist
- (3) bez szwu
- (4) bezproblemowe dopasowanie hist
- (5) surowy rgb
- (6) surowe przewidywanie
- (Warunkowo) Zamaskowane dopasowanie hist? ( tak / nie ) :
- (Warunkowo) Próg dopasowania Hist ( 0..255 ) :
- Wybierz tryb maski:
- (0) pełny
- (1) ds
- (2) wyuczony-prd (3) wyuczony-dst (4) wyuczony-prd*uczony-dst (5) wyuczony-prd+uczony
- (6) XSeg-prd
- (7) XSeg-dst
- (8) XSeg-prd*XSeg-dst
- (9) wyuczony-prd*uczony-dst*XSeg-prd*XSeg-dst
- Wybierz modyfikator maski erozji ( -400..400 )
- Ustal modyfikator maski rozmycia ( 0..400 )
- Ustaw moc rozmycia ruchu (0..100)
- Użyj trybu dwuprzebiegowego? ( t/n ?: pomoc )
- Ustal pre_sharpen power ( 0..100 ?:help )
- Zastosuj wyjściowy modyfikator skali twarzy ( -50..50 )
- Transfer koloru na przewidywaną twarz ( rct/lct/mkl/mkl-m/idt/idt-m/sot-m/mix-m )
- Uruchom tryb wyostrzania:
- (0) Brak
- (1) pudełko
- (2) gaussowski
- Zastosuj moc superrozdzielczości ( 0..100 ?:help ):
- Uruchom degradację obrazu według mocy denoise ( 0..500 ) :
- Ustaw degradację obrazu o dwusześcienną moc przeskalowania ( 0..100 ) :
- Pogorszenie mocy koloru końcowego obrazu ( 0..100 ) :
Eksportowanie do przetwarzania końcowego –
Możesz użyć połączonych sekwencji obrazów i masek w oprogramowaniu do przetwarzania końcowego jako zamiennik lub dodatek do fuzji DeepFaceLab.
Prawdopodobnie będziesz potrzebować tych elementów:
- Oryginalne wideo docelowe
- Wyodrębnione ramki docelowe
- Scalona sekwencja obrazów klatek
- Scalona sekwencja obrazu maski
Zaimportuj te sekwencje obrazów do oprogramowania do edycji lub przetwarzania końcowego. Twoje oprogramowanie może zapewniać określony sposób importowania sekwencji obrazów, w przeciwnym razie poszukaj dokumentacji lub samouczka. Następnie możesz użyć scalonych obrazów masek, aby utworzyć otoczkę dla scalonych obrazów ramek. Następnie powinieneś mieć swobodę modyfikowania matowania, poprawiania kolorów i malowania przeszkód. Niektórzy twórcy używają wielu masek, połączonych sekwencji obrazów z różnymi ustawieniami, a nawet wielu modeli i typów twarzy do tworzenia zaawansowanych kompozycji.
Krok 8: Scal obrazy klatek z wideo
Sztuczna inteligencja zamiana twarzy na wideo
Ostatnią częścią całego procesu jest połączenie nowych obrazów klatek deepfake w plik wideo z oryginalnym docelowym dźwiękiem.
Uruchom: 8) połączył się z *.bat
Połącz końcową sekwencję obrazów z docelowym filmem. Generuje wynik.* i maskę_wyniku.* w folderze obszaru roboczego.
- Szybkość transmisji pliku wyjściowego w MB/s : Wybierz szybkość transmisji wideo.
Zamknij okno po zakończeniu scalania.
| Scal do formatu wideo | Opis |
|---|---|
| 8) połącz się z avi.bat | Połącz ostateczną sekwencję obrazów z docelowym wideo jako AVI. Szybkość transmisji pliku wyjściowego w MB/s : Wybierz szybkość transmisji wideo. Generuje wynik.avi i wynik_maska.avi w folderze obszaru roboczego. |
| 8) scal się z movlossless.bat | Scal ostateczną sekwencję obrazów z docelowym wideo jako bezstratne MOV. Generuje result.mov i result_mask.mov w folderze obszaru roboczego. |
| 8) połącz się z bezstratnym plikiem mp4.bat | Połącz ostateczną sekwencję obrazów z docelowym wideo jako bezstratny MP4. Generuje result.mp4 i result_mask.mov w folderze obszaru roboczego. |
| 8) scal się z mp4.bat | Scal ostateczną sekwencję obrazów z docelowym wideo jako skompresowany MP4. Szybkość transmisji pliku wyjściowego w MB/s : Wybierz szybkość transmisji wideo. Generuje wynik.mp4 i wynik_maska.mp4 w folderze obszaru roboczego. |
DeepFaceLab 2.0 połączył się z formatami wideo
Krok 9: Zobacz wideo z wynikami
Wreszcie jesteś gotowy, aby obejrzeć film deepfake. Przejdź do folderu obszaru roboczego, a zobaczysz kilka nowych plików.
Odtwórz plik oznaczony jako „wynik.*” (np. wynik.mp4).
Artykuł ten jest tłumaczeniem wprowadzającym korekty mające na celu prostszą i wygodniejszą prace w Polskiej Lokalizacji DeepFakeVFX
Strona główna
Cyfrowa obróbka obrazu
ChatGPT sztuczna inteligencja rewolucja
Zachęcam do innych poradników:
Whisper system automatycznego rozpoznawania mowy
Przekierowywanie Portów na Routerze
Popraw bezpieczeństwo komputera
Sztuczna inteligencja – ChaptGPT
Sztuczna inteligencja zamiana twarzy DeepFake
Anonimowość w sieci – Topowe programy
Transformers = sztuczna inteligencja